このこの記事は、【中編】からの続きです。
目標到達プロセスデータ探索
目標到達プロセスデータ探索では、ユーザーがコンバージョンに至るまでのステップをビジュアル表示し、各ステップでのユーザーの動向をすばやく確認できます。たとえば、見込み顧客がどのように買い物客になり、その後どのように顧客に変わるか、一見客がどのようにリピーターになるのかといったことです。この情報から、非効率なカスタマー ジャーニーや、放棄されるカスタマー ジャーニーの改善を図ることができます。
公式ヘルプ:https://support.google.com/analytics/answer/9317498?hl=ja&ref_topic=9266525
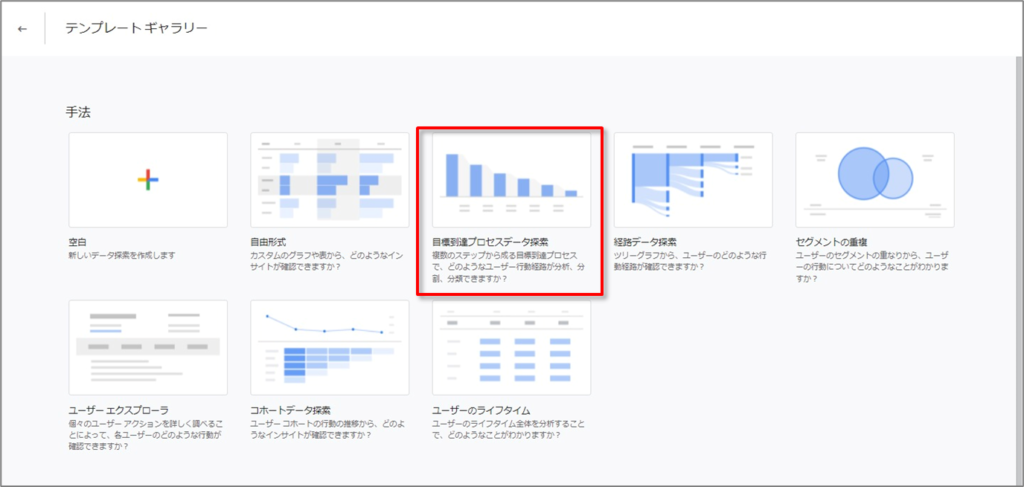
画面上部で 「目標到達プロセスデータ探索」テンプレートを選択します。
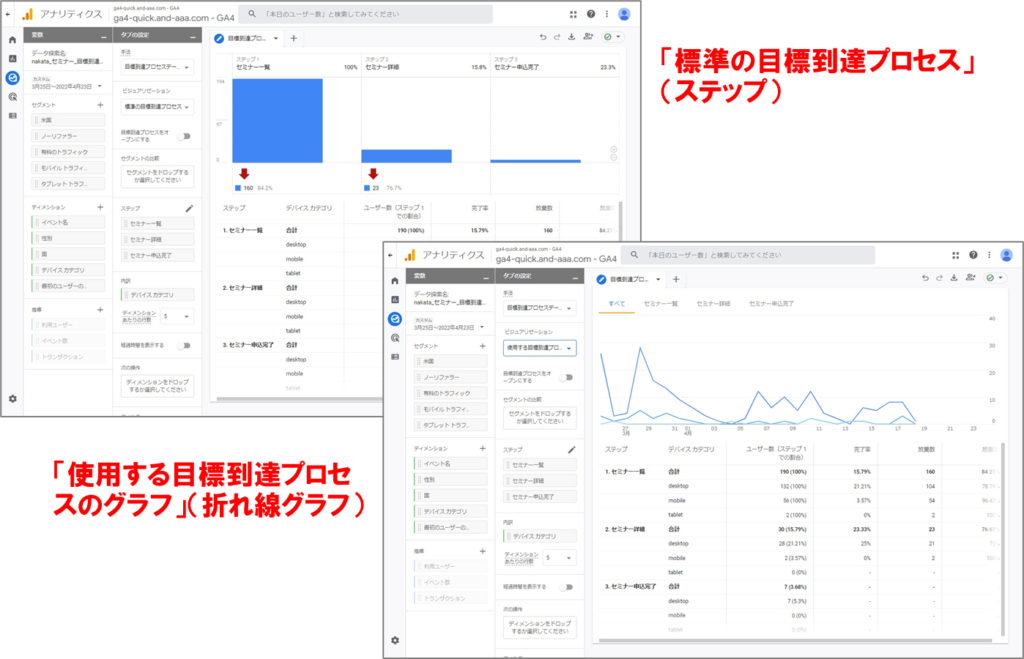
「標準の目標到達プロセス」(ステップ)または 「使用する目標到達プロセスのグラフ」(折れ線グラフ)
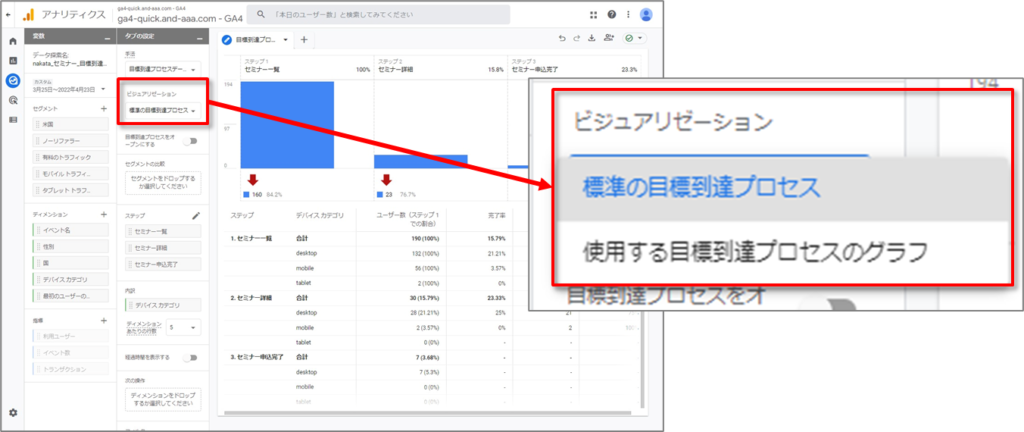
「標準の目標到達プロセス」(ステップ)または 「使用する目標到達プロセスのグラフ」(折れ線グラフ)を選択します。使用する目標到達プロセスのグラフでは、すべてのステップを同時に表示することも、ビジュアリゼーションの上部にあるステップ名をクリックして特定のステップを詳しく調べることもできます。
目標到達プロセスのステップの編集
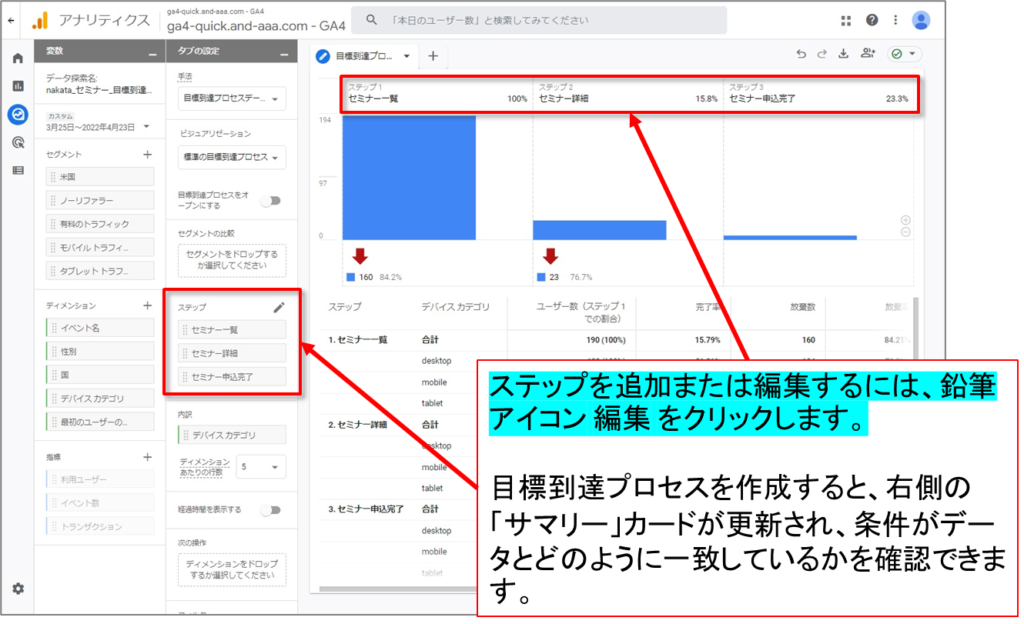
ステップを追加または編集するには、鉛筆アイコン 編集 をクリックします。
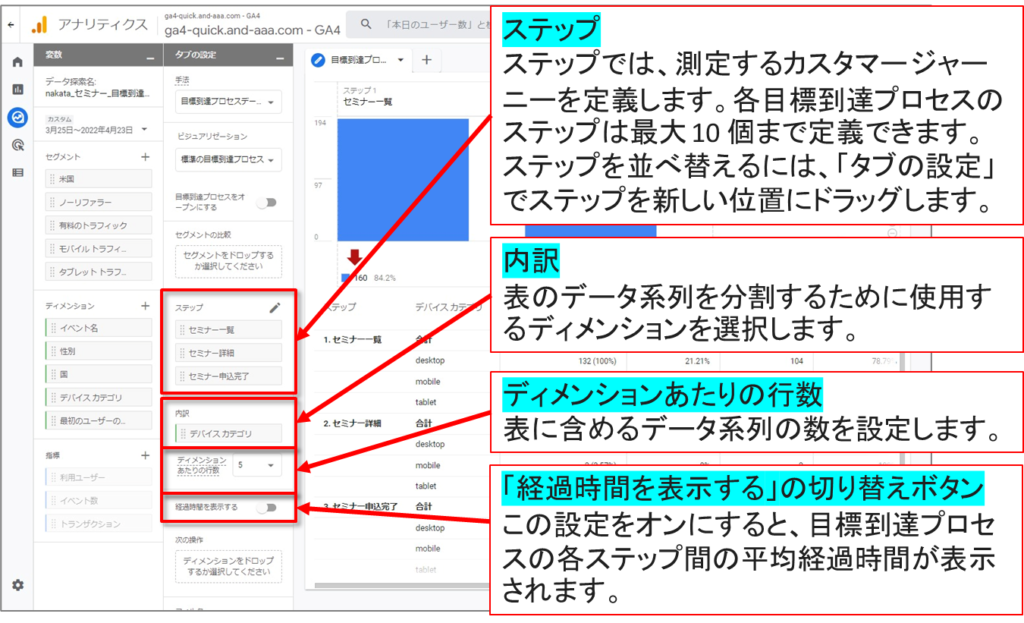
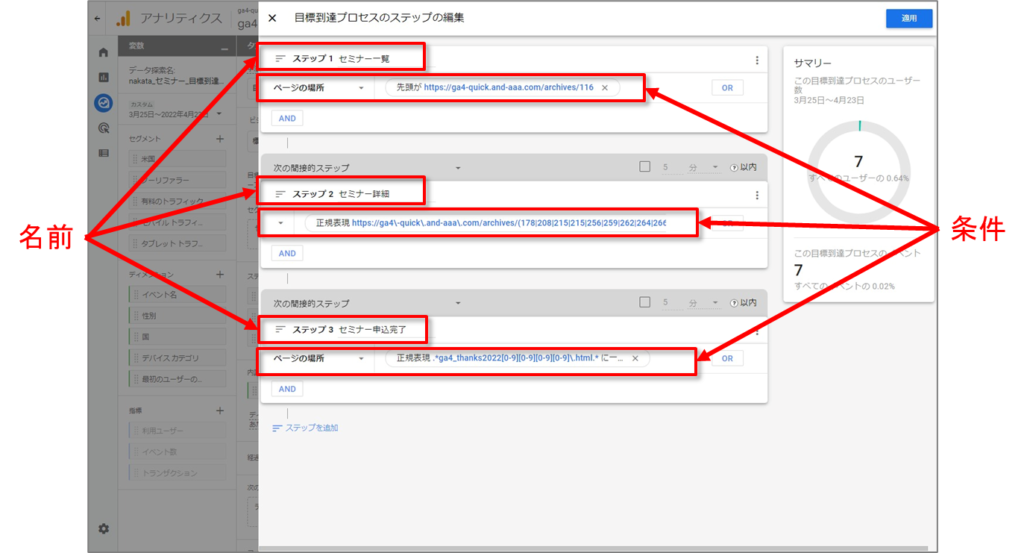
各ステップにわかりやすい名前を付けます。 ユーザーが目標到達プロセスの各ステップに含まれる条件を、1 つ以上追加します。
条件は、ユーザーがトリガーするイベント、またはユーザーが共有するディメンション値に基づいて設定できます。たとえば、「ユーザー獲得発生キャンペーン」ディメンションが「サマーセール」と等しい、または「purchace」イベントのパラメータ「value」を「>= 100」と設定します。
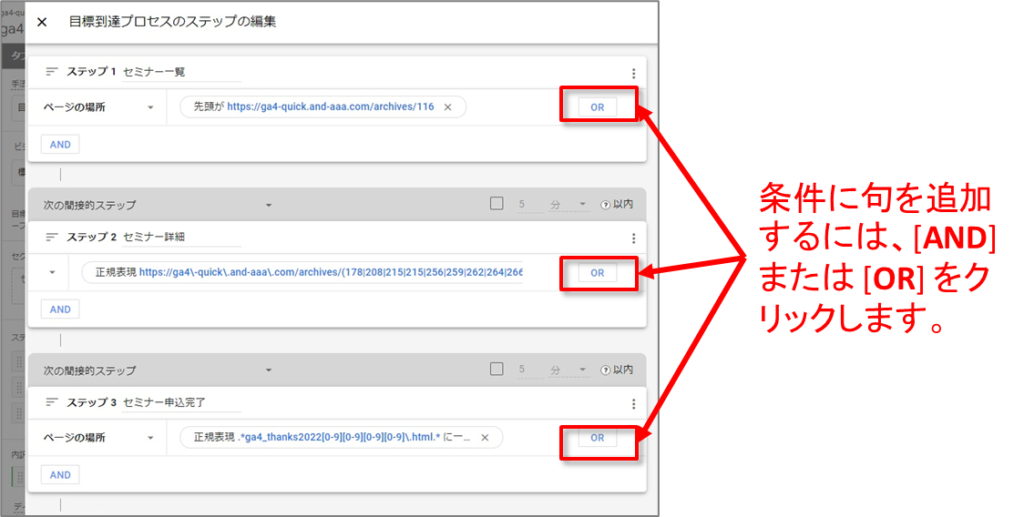
条件に句を追加するには、[AND] または [OR] をクリックします。
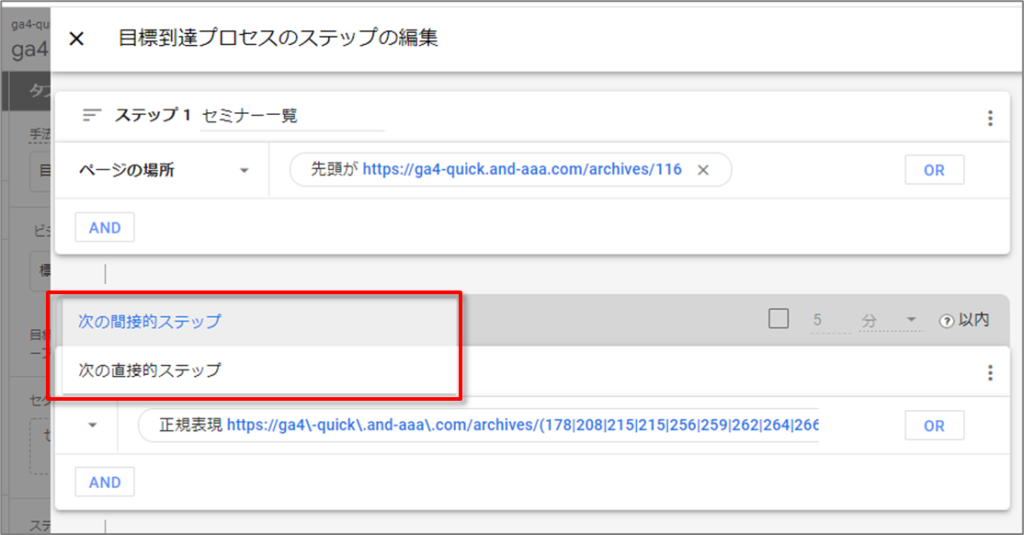
追加するステップと前のステップの関係(「次の間接的ステップ」または「次の直接的ステップ」)を指定します。
・「次の間接的ステップ」の場合、前のステップとの間に別のアクションが挟まっていても、プロセスを辿ったものと判定されます。
・「次の直接的ステップ」の場合、前のステップの直後に所定のアクションを完了しなければ、プロセスを辿ったものと判定されません。
「目標到達プロセスをオープンにする」の切り替えボタン
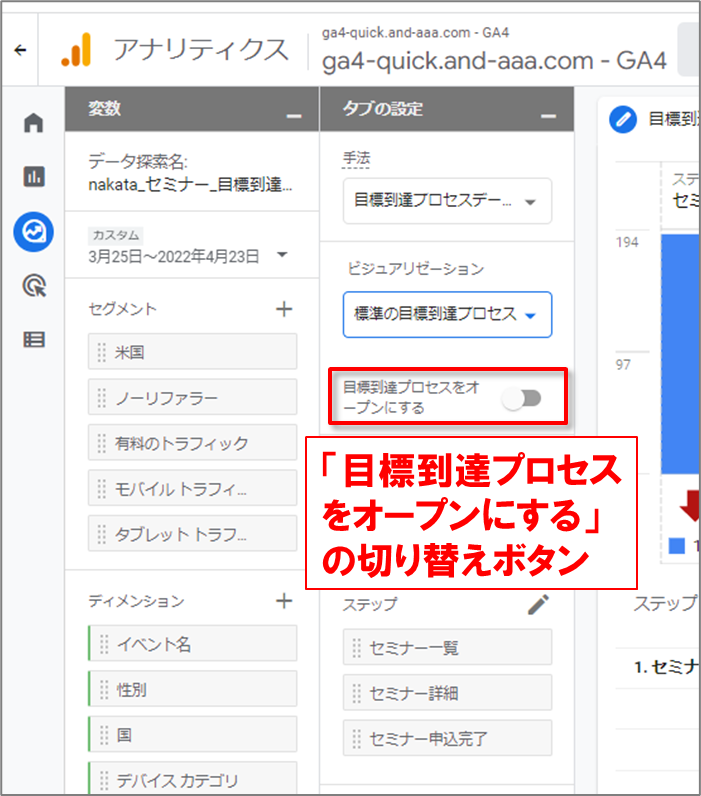
目標到達プロセスは、ユーザーがプロセスに入ったかどうかを判定する方法によって、「オープン」型と「クローズド」型に分けられます。
オープンな目標到達プロセスでは、プロセスの途中のステップから開始したユーザーもすべてカウントされます。
クローズドな目標到達プロセスでは、プロセスの最初のステップを経たユーザー以外は無視されます。
いずれの方式でも、ユーザーがプロセスを辿ったと判定されるのは、指定の順序どおりにステップを踏んだ場合のみです。途中のステップを抜かした場合は、後続のステップを完了しても、プロセス内の行動としてはカウントされません。
例
次の 2 種類の目標到達プロセスを作成してあるとします。
| 目標到達プロセス | ステップ | オープン / クローズド |
| 目標到達プロセス 1 | A、B、C | オープン |
| 目標到達プロセス 2 | A、B | クローズド |
4 人のユーザーが、目標到達プロセスの期間内にサイトを訪問し、それぞれ以下のステップの条件を満たす行動を取ったとします。
| ユーザー | 条件を満たしたステップ |
| 1 | A、B、C |
| 2 | B、C |
| 3 | A、C |
| 4 | C |
各目標到達プロセスにおいて、各ユーザーが完了したと判定されるステップは次のとおりです。
目標到達プロセス 1:
| ユーザー | 完了したと判定されるステップ |
| 1 | A、B、C |
| 2 | B、C |
| 3 | A |
| 4 | C |
目標到達プロセス 2:
| ユーザー | 完了したと判定されるステップ |
| 1 | A、B、C |
| 3 | A |
説明:
「目標到達プロセス 1」 はオープン型なので、途中のステップから開始したユーザーもカウントされます。4 人全員がプロセスに入ったものと判定されていますが、順序どおりに辿ったステップでなければカウントされないため、ユーザー 3 はステップ A のみを完了した扱いです(ステップ B を抜かしたため、ステップ C の完了は無視されています)。
「目標到達プロセス 2」 はクローズド型なので、最初のステップ(ステップ A)を経たユーザー以外は無視されます。このため、カウントされているのはユーザー 1 および 3 のみです。
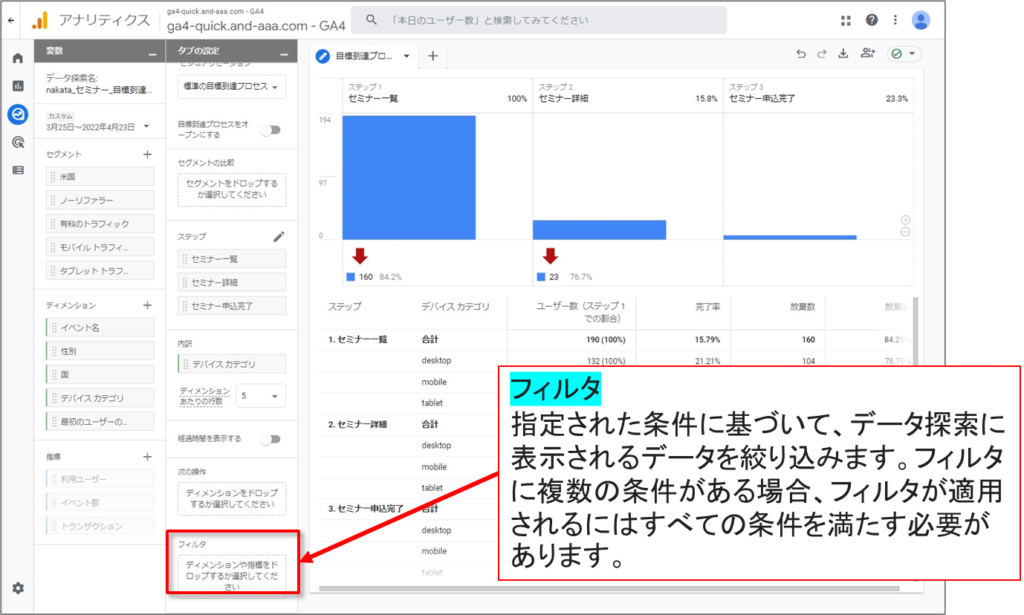
セグメントの比較
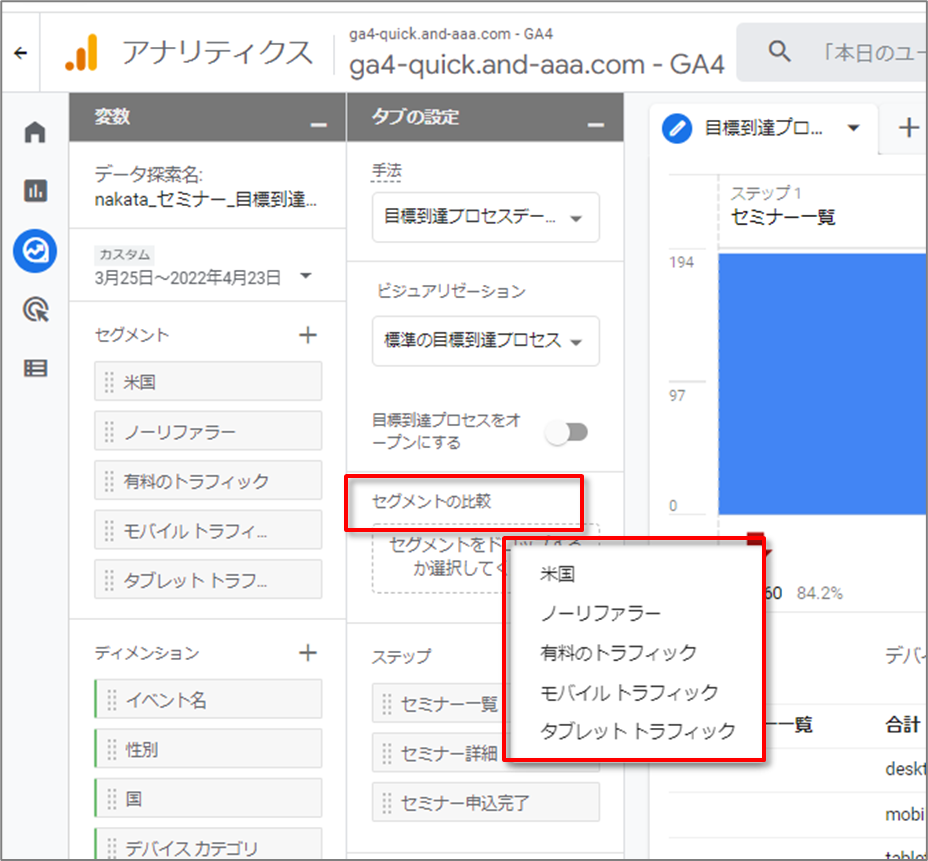
最大 4 つのセグメントを適用して、特定のユーザーセットのみに焦点を当てることができます。データ表を右クリックすると、データからセグメントを作成できます。
ユーザー エクスプローラ
ユーザー エクスプローラを使用すると、アプリとウェブサイトの両方でプロパティにアクセスしたことのあるユーザーなど、特定のユーザー グループを選択したり、個々のユーザーの利用状況ごとにドリルダウンしたりすることができます。
個別のユーザーの行動が重要になるのは、ユーザーごとに異なるユーザー エクスペリエンスを提供したり、特定のユーザーフローについての分析やトラブルシューティングを行う場合です。たとえば、平均注文値が異常に大きいユーザーの行動を分析したり、注文時に問題が発生するポイントを確認する場合が該当します。
「ユーザー エクスプローラ」テンプレートを選択します。
ユーザー エクスプローラの仕組み
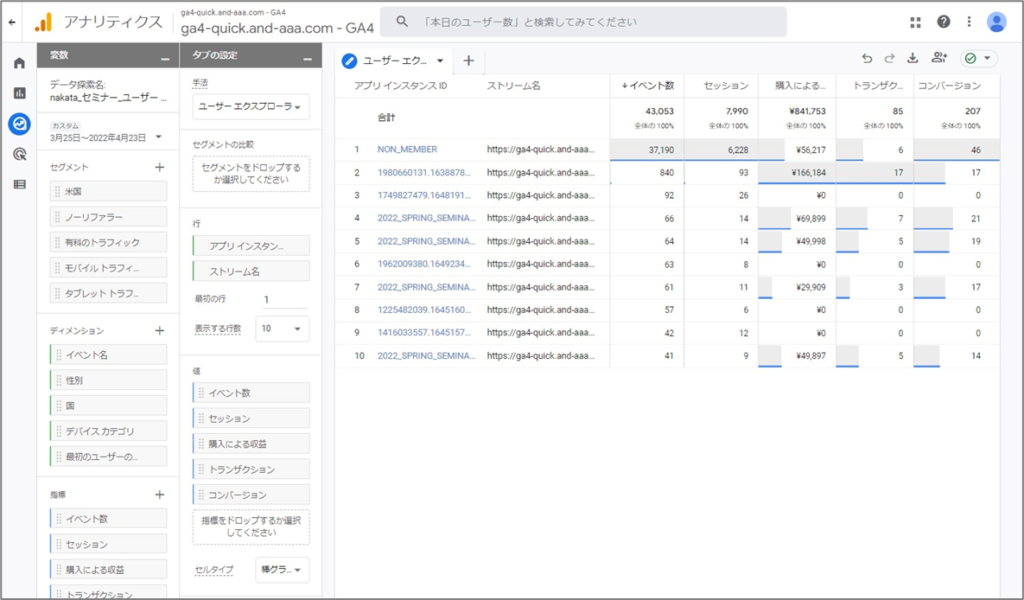
ユーザー エクスプローラには、既存のセグメントを構成するユーザーや、他のデータ探索手法の使用により生成された一時的なセグメントを構成するユーザーが表示されます。
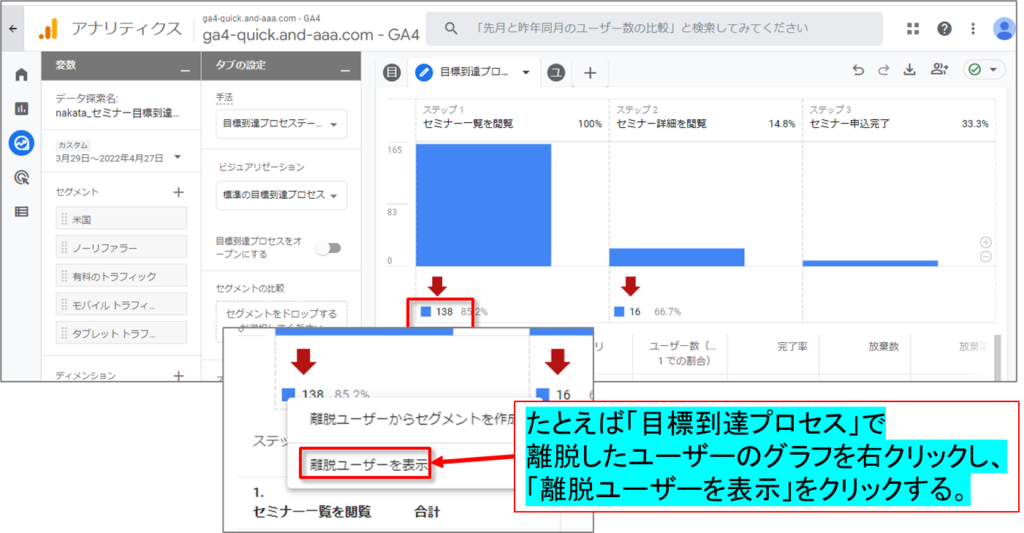
「他のデータ探索手法の使用により生成された一時的なセグメントを構成するユーザーが表示されます。」とは?
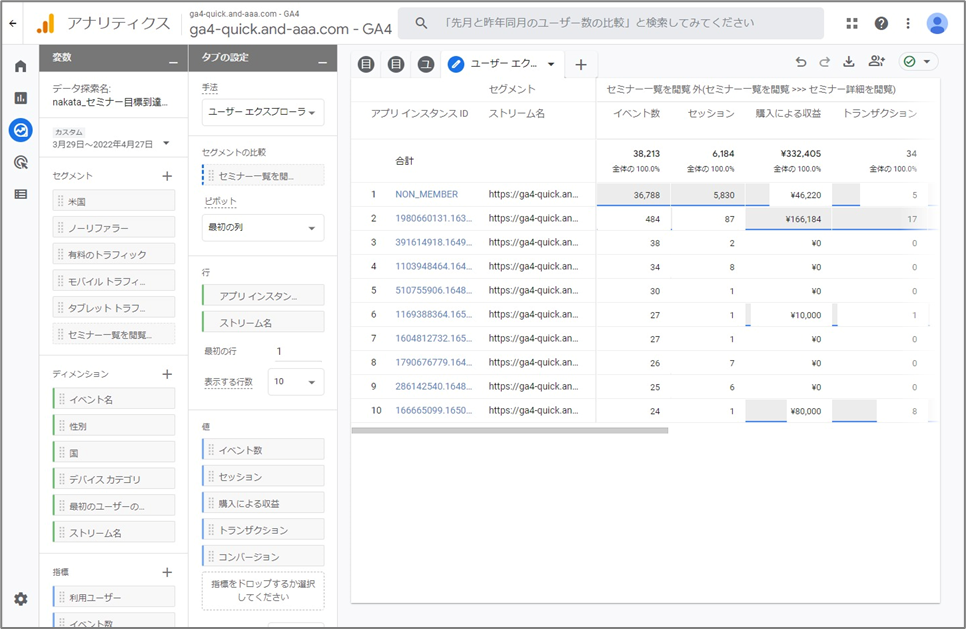
画面が「ユーザー エクスプローラー」の画面になり、 「目標到達プロセス」で離脱したユーザーの「ユーザー エクスプローラ」が表示されました。
カスタマイズする
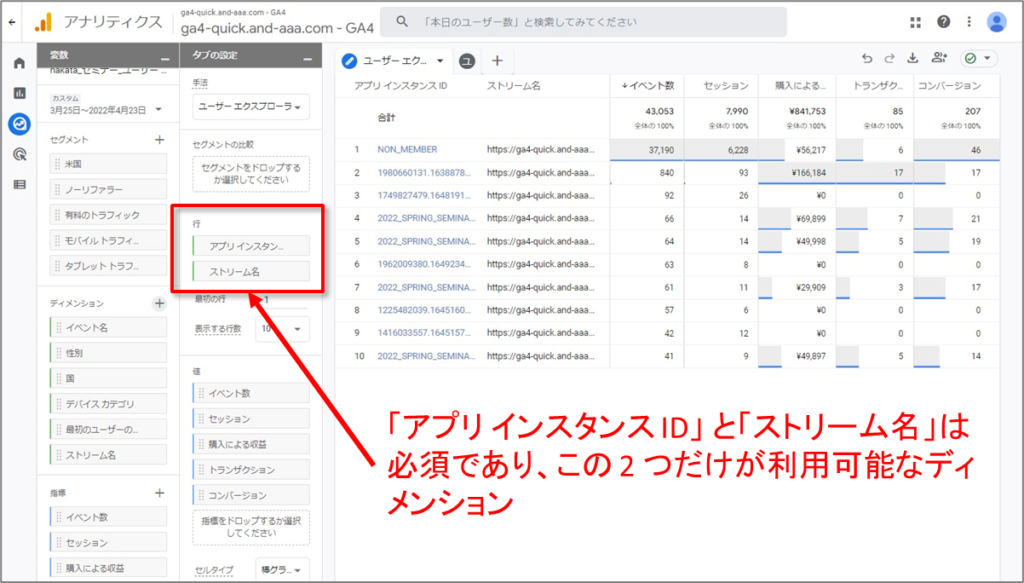
「アプリ インスタンス ID」 と「ストリーム名」は必須であり、この 2 つだけが利用可能なディメンションです。ただし、指標については、「タブの設定」 パネルの 「値」 セクションで追加したり、削除したりすることで変更できます。
行を調整する
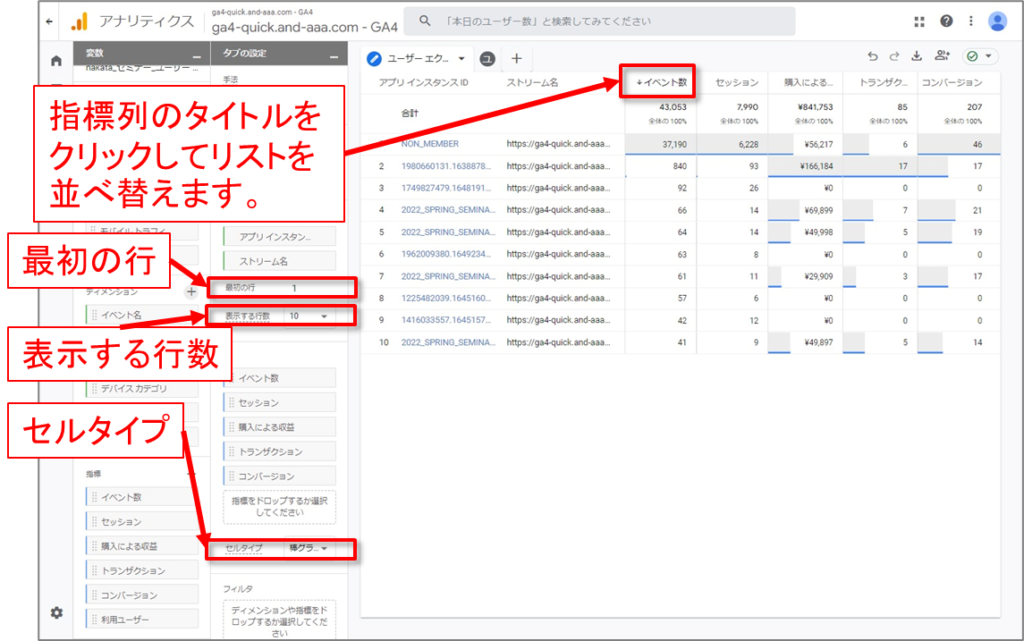
行を調整する
デフォルトでは、ユーザーデータ探索ではセッションごとに上位 10 人のユーザーが表示されます。表示されるユーザー数をタブ設定で調整する方法は次のとおりです。
•[表示する行数] では、リスト内の行数を調整します。
•[最初の行] では、リストの開始行を決定します。
•[並べ替え] では、指標列のタイトルをクリックしてリストを並べ替えます。
•[セルタイプ] を使用すると、リスト内の指標を書式なしテキストとして表示したり、色付きのバーやヒートマップを使って視覚表示を強化したりすることができます。
個々のユーザーの利用状況を表示する
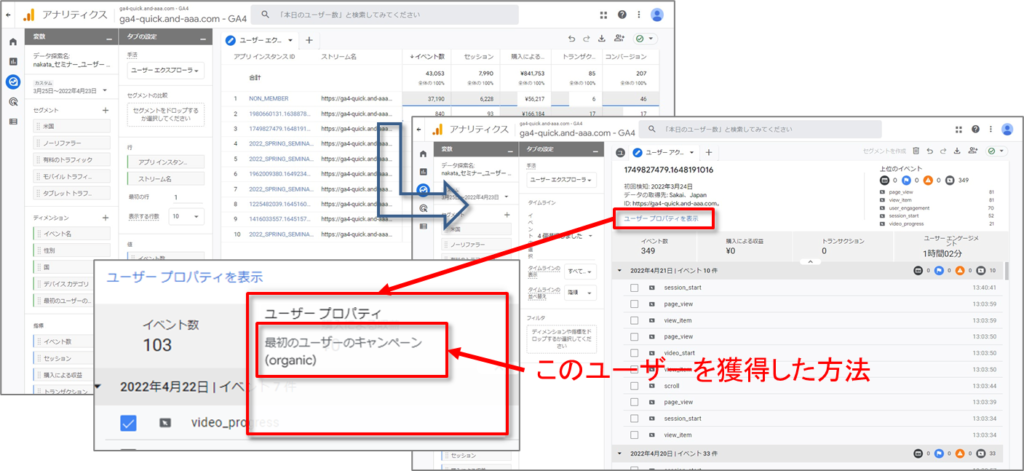
ユーザーデータ探索の表内にある特定の記録をクリックすると、個々のユーザーの利用状況を表示できます。
これにより、このユーザーを獲得した方法と時期に関する詳細に加え、サイトやアプリでそのユーザーによってトリガーされたイベントのタイムラインが日付別に表示されます。
ユーザー エクスプローラーのUI
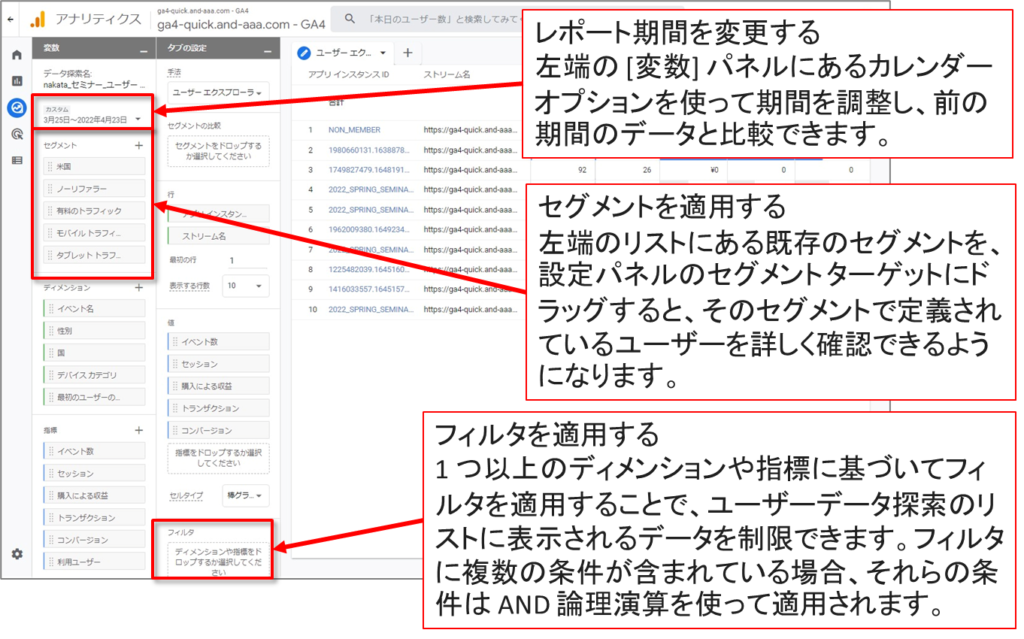
「タイムライン」セクションのオプションを使用
左側にある 「タイムライン」セクションのオプションを使用すると、以下のことができます。
•選択したイベントを表示
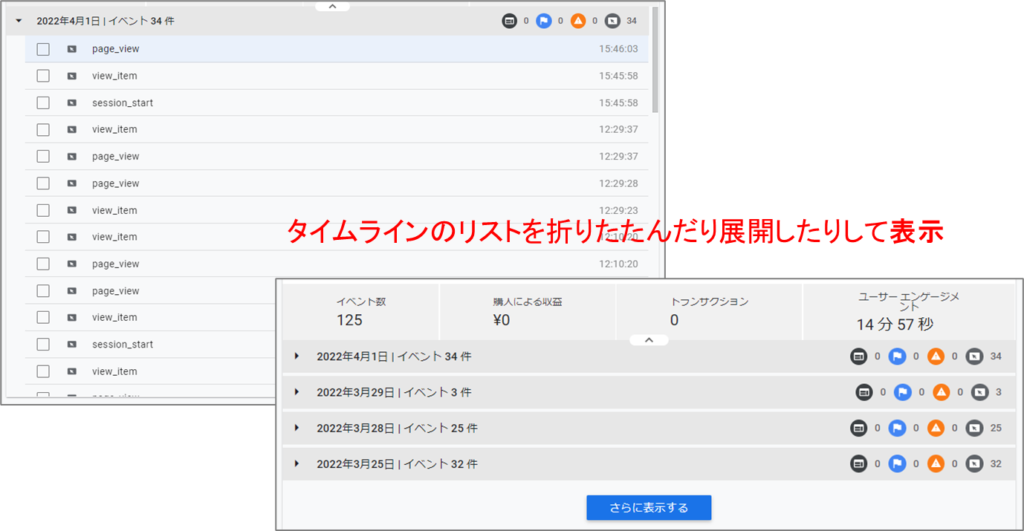
•タイムラインのリストを折りたたんだり展開したりして表示
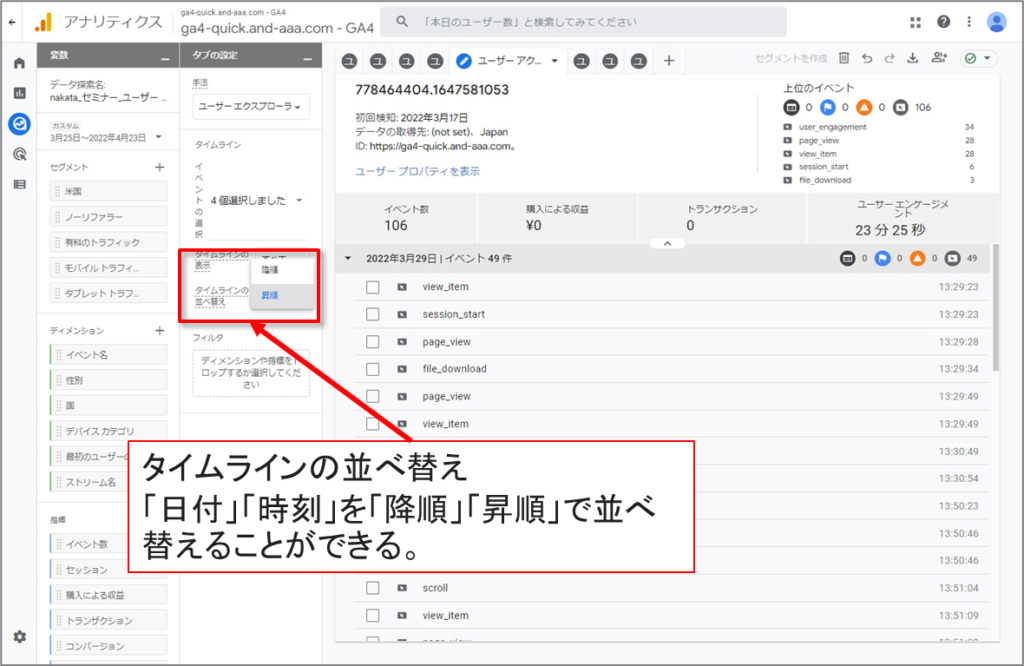
タイムラインのイベントを並べ替え
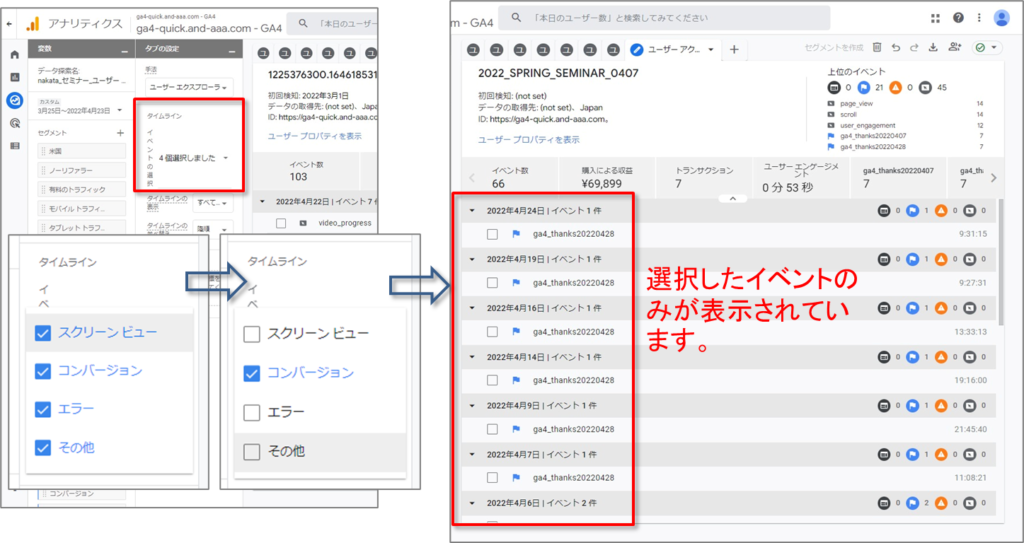
選択したイベントを表示
•「イベントの選択」で「タイムライン」で表示するイベントを選択することができます。
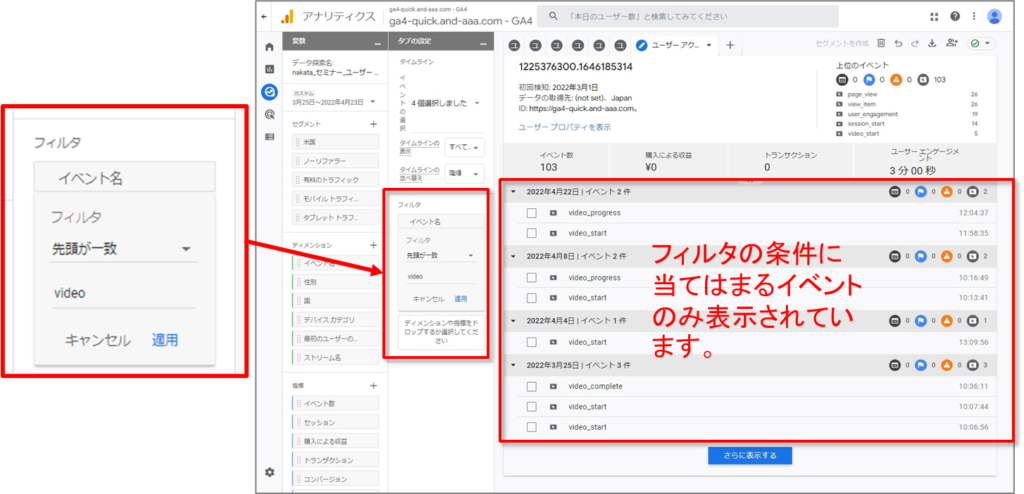
上記の例では、「イベント名」:「先頭が一致」=「video」というフィルターを掛けています。
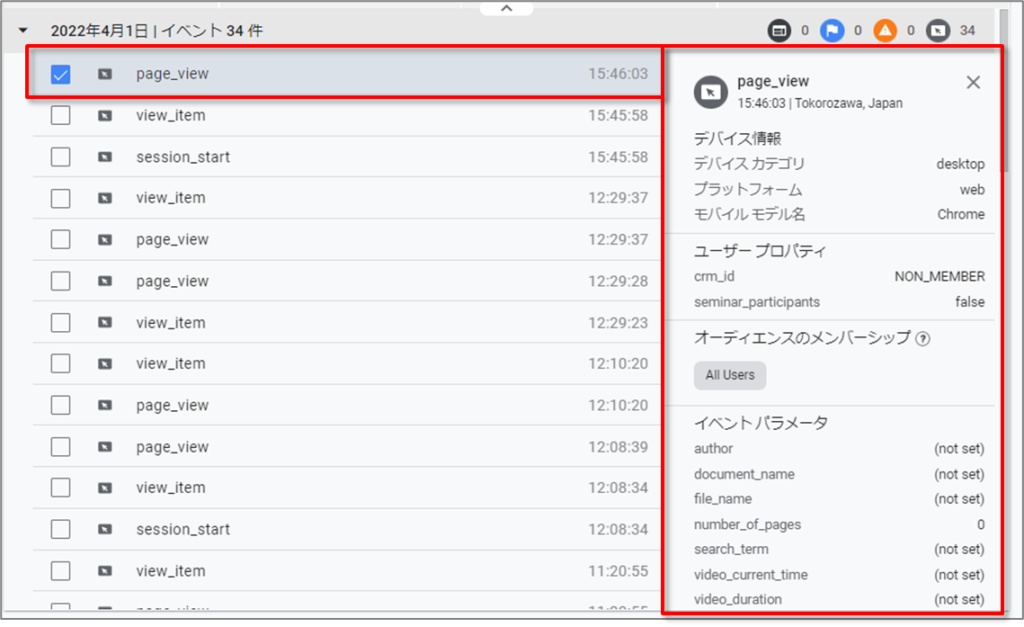
個々のユーザーからセグメントを作成する
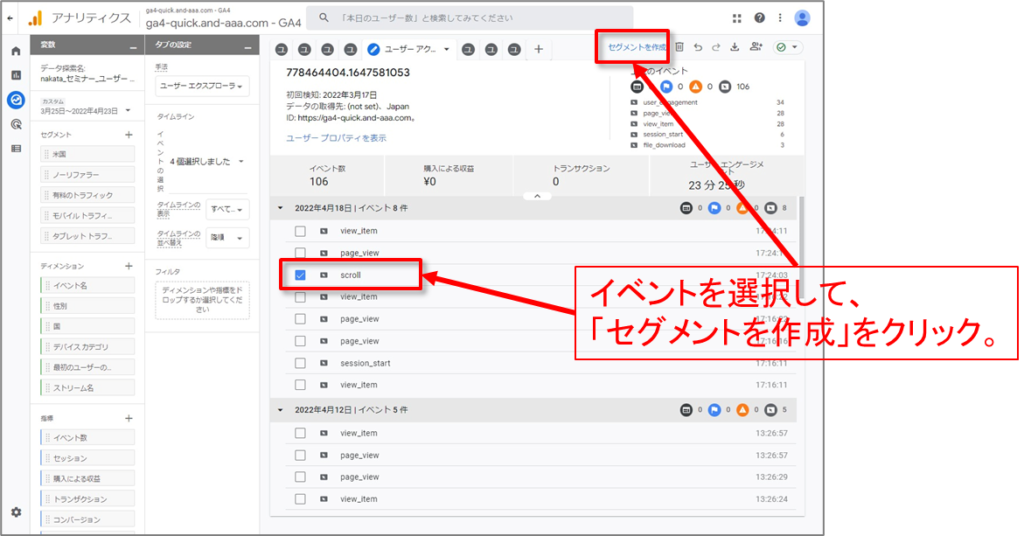
タイムラインでは、1 つまたは複数の個々のユーザーのイベントを選択することで、特定のイベント グループを含むすべてのユーザーのセグメントを作成できます。
イベントを作成後、右上の「セグメントを作成」をクリックします。
作成されたセグメントを必要に応じて編集、保存すると、より詳細なデータ探索やレポート作成に使用することが可能です。
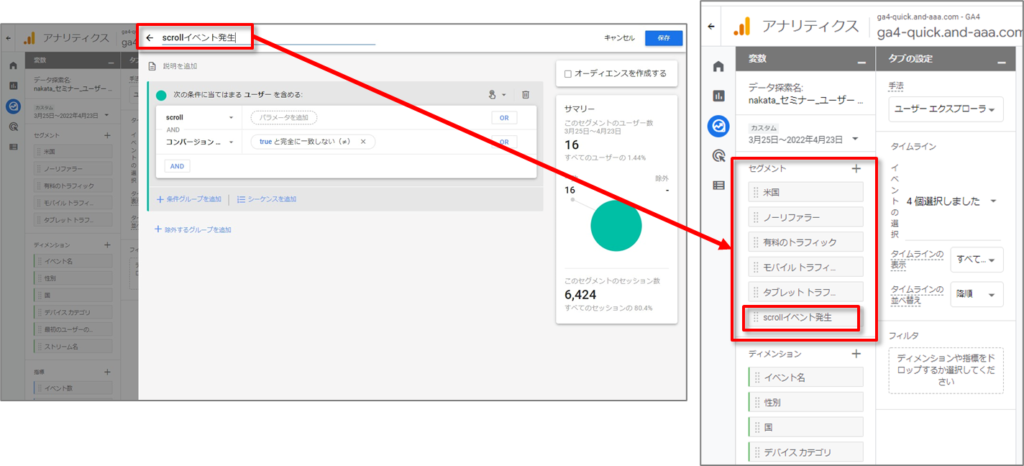
保存すると、「変数」列の「セグメント」に入ります。
ユーザーデータを削除する
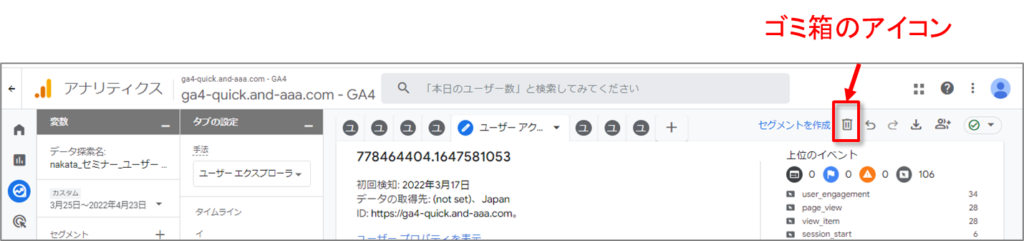
右上にある ゴミ箱のアイコン をクリックします。
現在表示されているユーザーのデータは、24 時間以内にユーザーデータ探索には表示されなくなり、その後 63 日以内に完全に削除されます。
自由形式
「自由形式のデータ探索」は、高度なカスタマイズ性と柔軟性を備えた分析手法です。たとえば次のような操作が可能です。
•表やグラフでデータを視覚化
•表の行や列を自在に組み替え
•複数の指標を並べて比較
•行をネストしてデータをグループ化
•セグメントやフィルタで自由形式のデータ探索対象を絞り込み
•選択したデータからセグメントやオーディエンスを作成
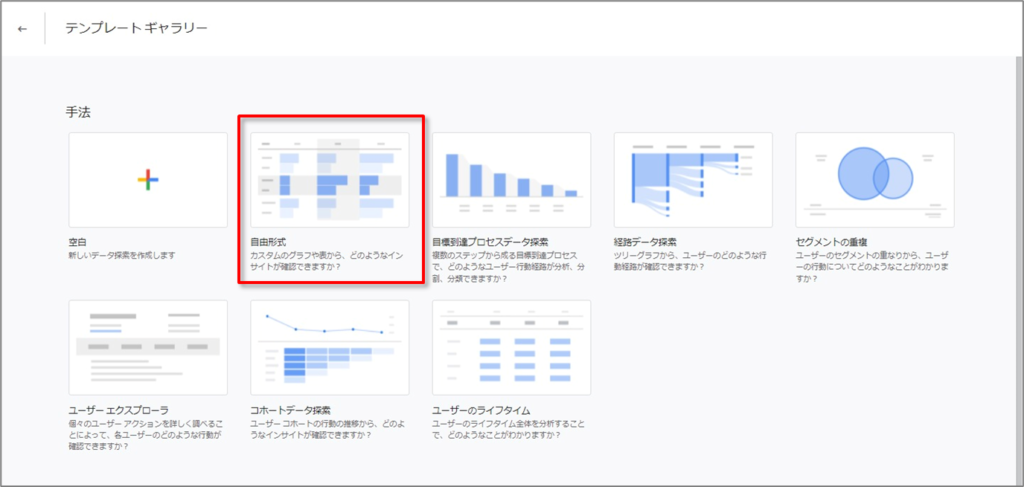
「自由形式」テンプレートを選択します。
「自由形式」のUI
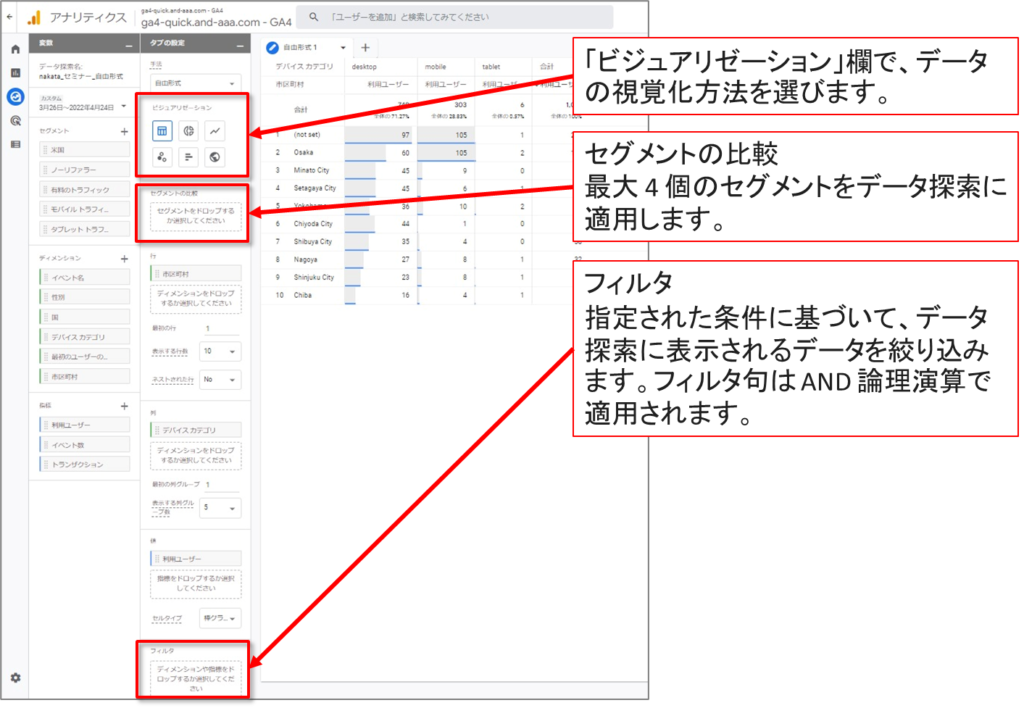
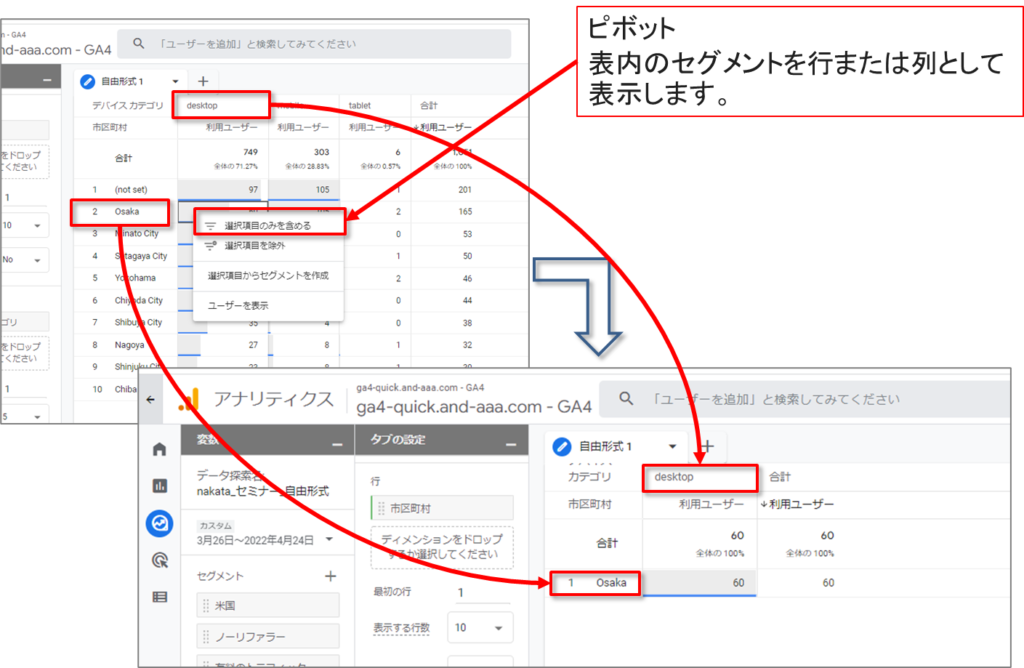
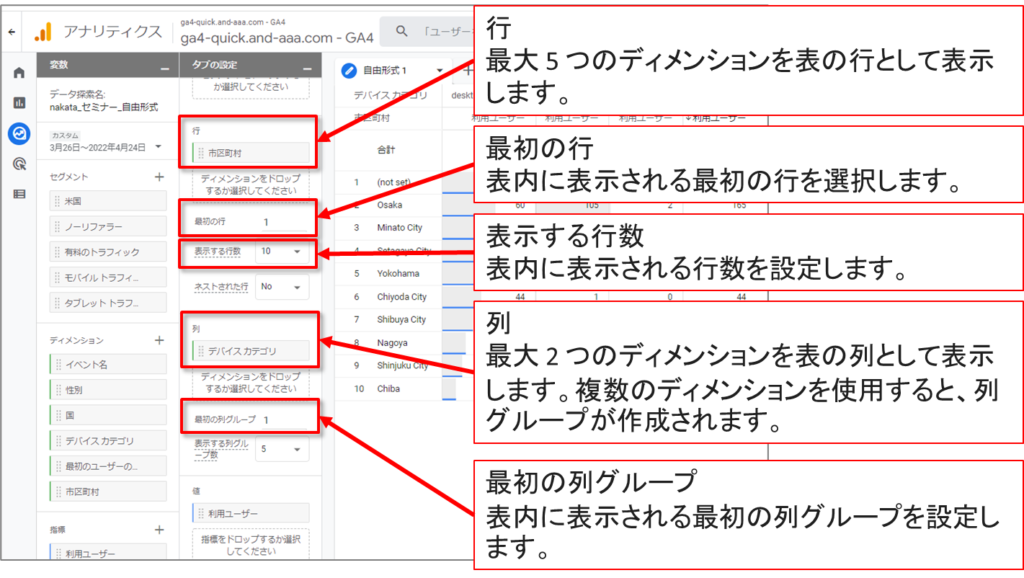
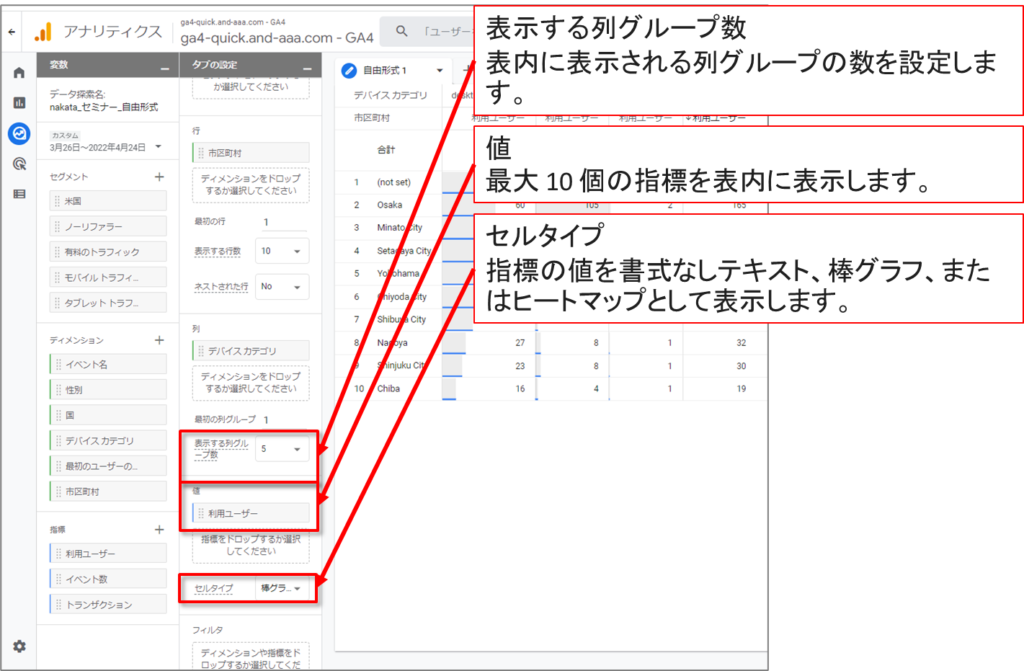
「自由形式」-「表のオプション」のUI
「自由形式」-「円グラフのオプション」のUI
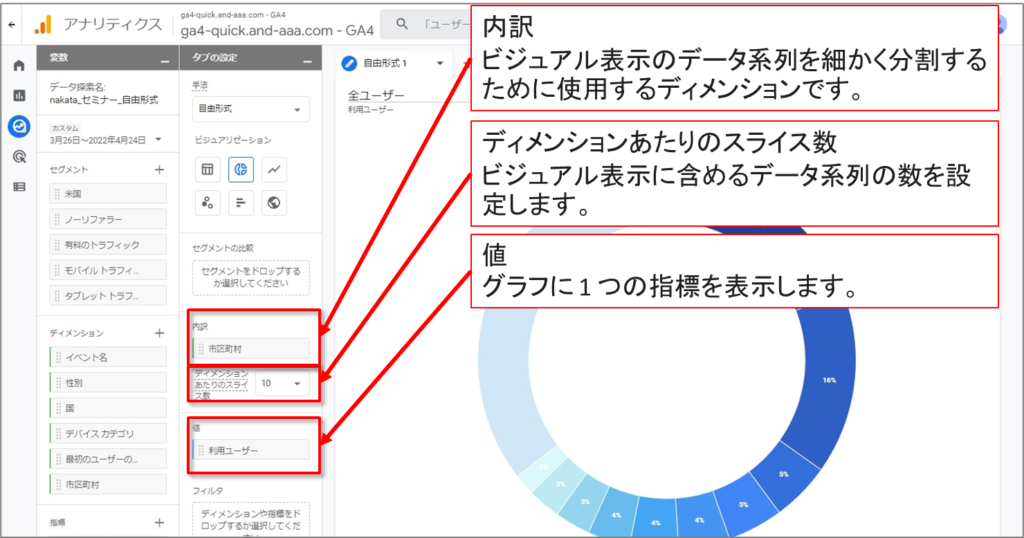
「自由形式」-「折れ線グラフのオプション」のUI
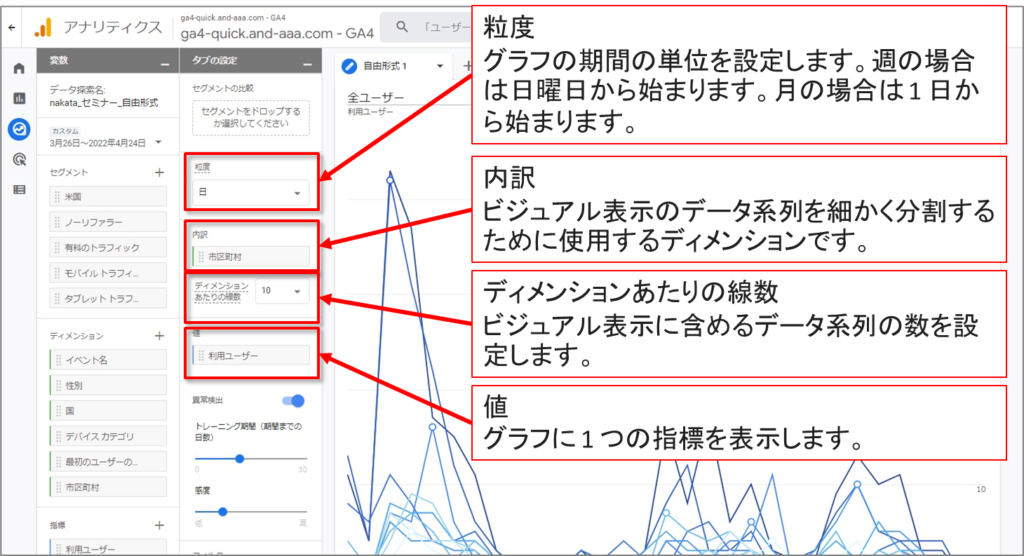
「折れ線グラフのオプション」の異常検出
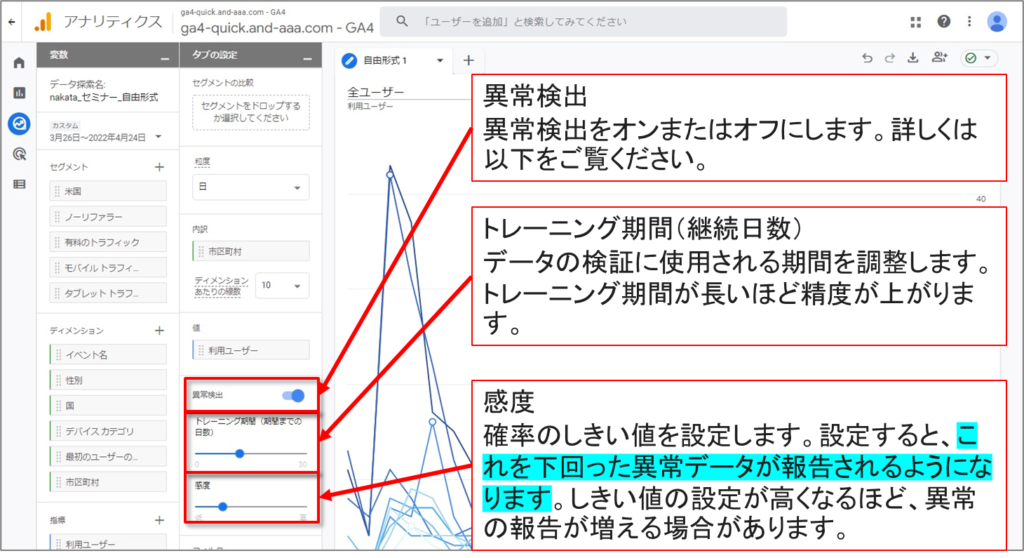
「異常検出」の解説
異常検出では、折れ線グラフを使ってデータの外れ値(統計学において、他の値から大きく外れた値)を特定できます。
折れ線グラフで異常検出を使用すると、データの外れ値を特定できます。このオプションは 「タブ設定」パネルではデフォルトで有効になっており、次の 2 つの設定で検出モデルを構成できます。
トレーニング期間(直前の期間):
表示される指標値を予測するために、現在選択されている期間の何日前からデータを異常検出モデルに使用するのかを決定します。
たとえば、現在選択されている期間が月の最初の 10 日間で、トレーニング期間を 7 日間に設定した場合、データはその月が始まる 7 日前から異常検出モデルに使用されます。
感度:
確率のしきい値を設定します。設定すると、これを下回った異常データが報告されるようになります。感度は、モデルの「考え方」には影響せず、データにラベルを付ける方法のみを指定します。特定の値で発生するポイントの確率は、モデルによって予測され、感度の影響は受けません。
たとえば、感度が 5% の場合、5% 未満の確率で発生するポイントは異常と見なされます。したがって、感度モデルを高くすると、より多くのデータが外れ値として報告される可能性があります。
異常検出モデルを定義すると、ベイズ統計の状態空間時系列モデル(英文資料:https://people.ischool.berkeley.edu/~hal/Papers/2013/pred-present-with-bsts.pdf)がトレーニング データに適用され、時系列に表示される指標の値が予測されます。
最後に、統計的有意性テストをもとにデータポイントが評価され、異常があれば報告されます。p 値(英文資料: https://en.wikipedia.org/wiki/P-value )のしきい値は、選択した感度に基づいて決定されます。
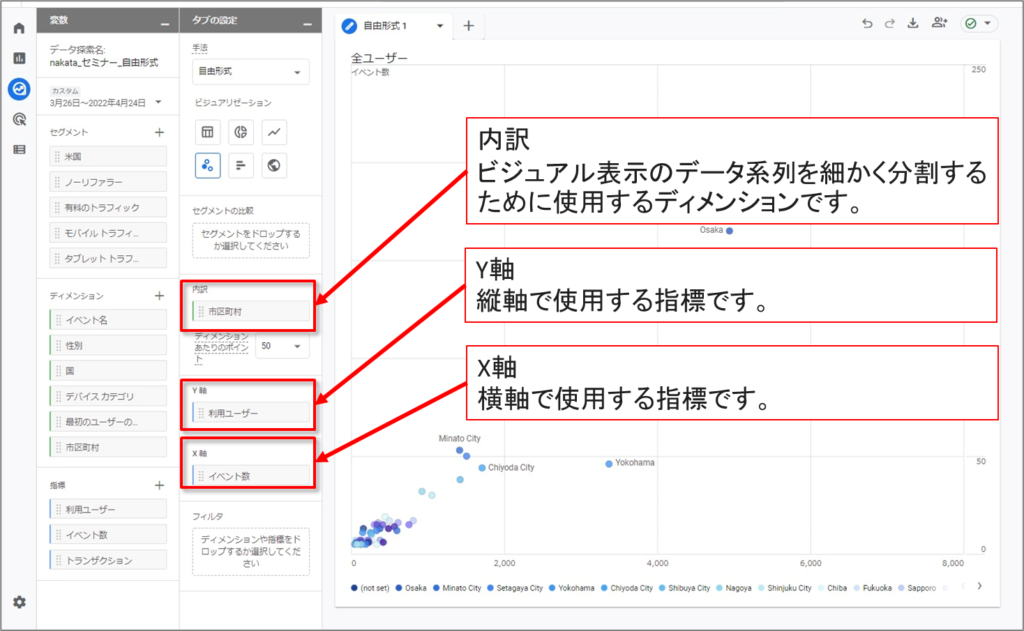
「自由形式」-「散布図のオプション」のUI
「自由形式」-「地図のオプション」のUI
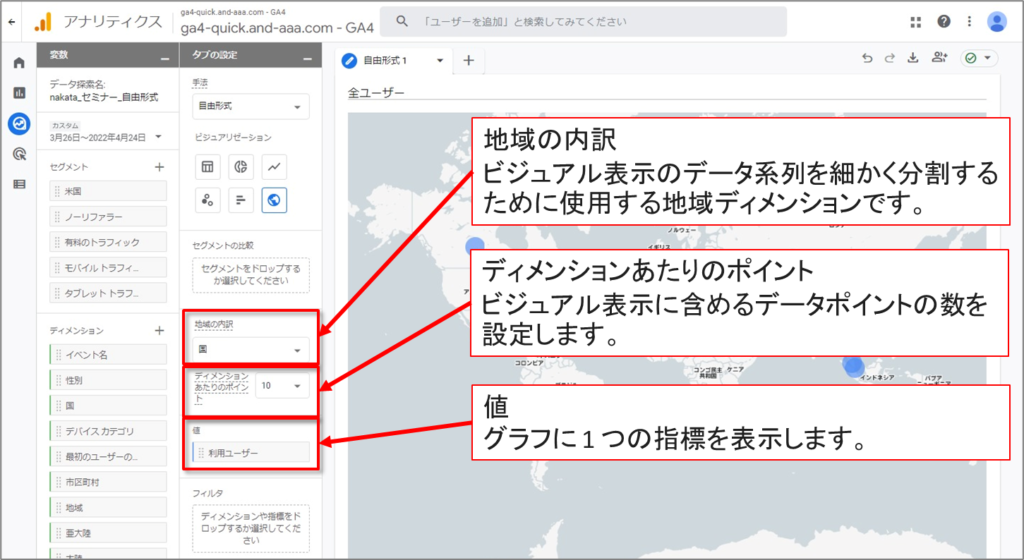
コホートデータ探索
コホートは、Google アナリティクスのディメンションを使用してこのレポートで表示できる、共通の特性を持つユーザーのグループです。たとえば、獲得日が同じユーザーはすべて同じコホートに属します。コホートデータ探索を行うと、アプリまたはサイト内での、時間の経過に伴うこれらのグループの行動を確認できます。
たとえば、新たに獲得したユーザーがサイト上でトランザクションを行うまでにかかる時間、そしてプロモーションを実施した週にその状況がどのように変化するかを把握できます。また、長期にわたり維持しているユーザー数と、デザインを新しく変えたアプリをリリースした直後に維持率が改善するかといったことも確認できます。
「コホートデータ探索」テンプレートを選択します。
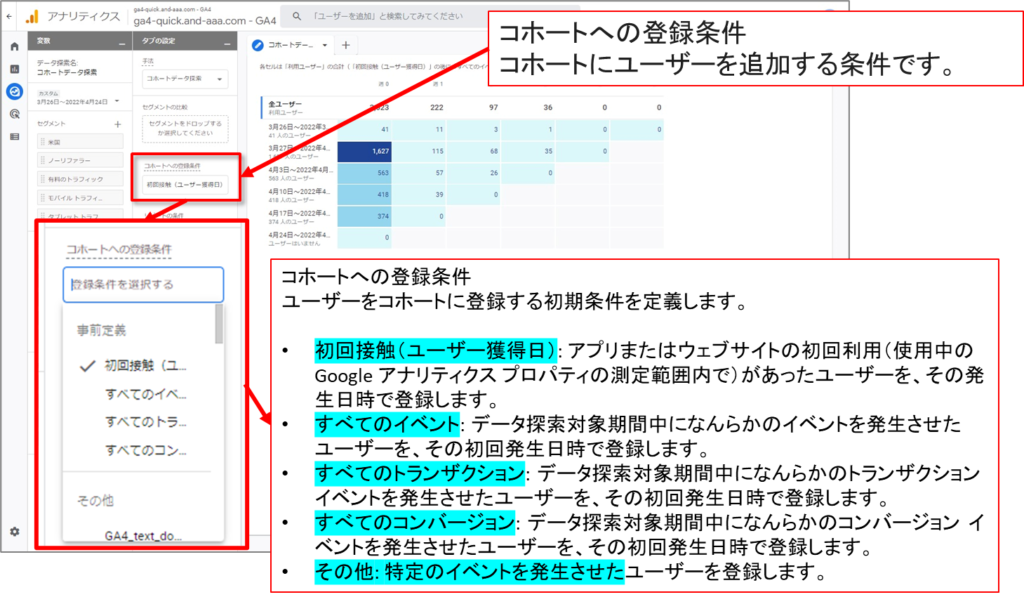
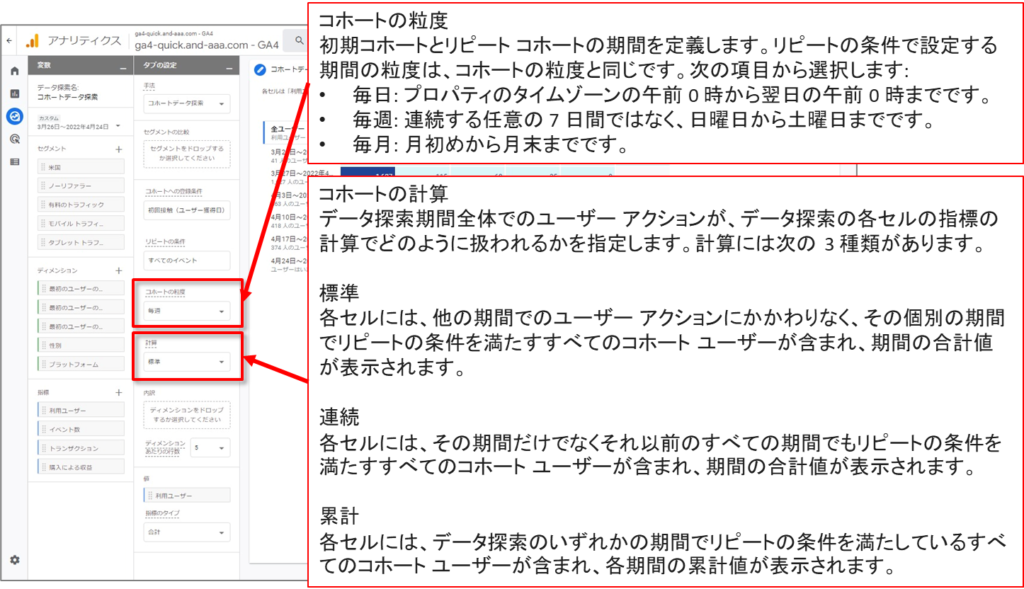
コホートデータ探索を設定する コホートへの登録条件
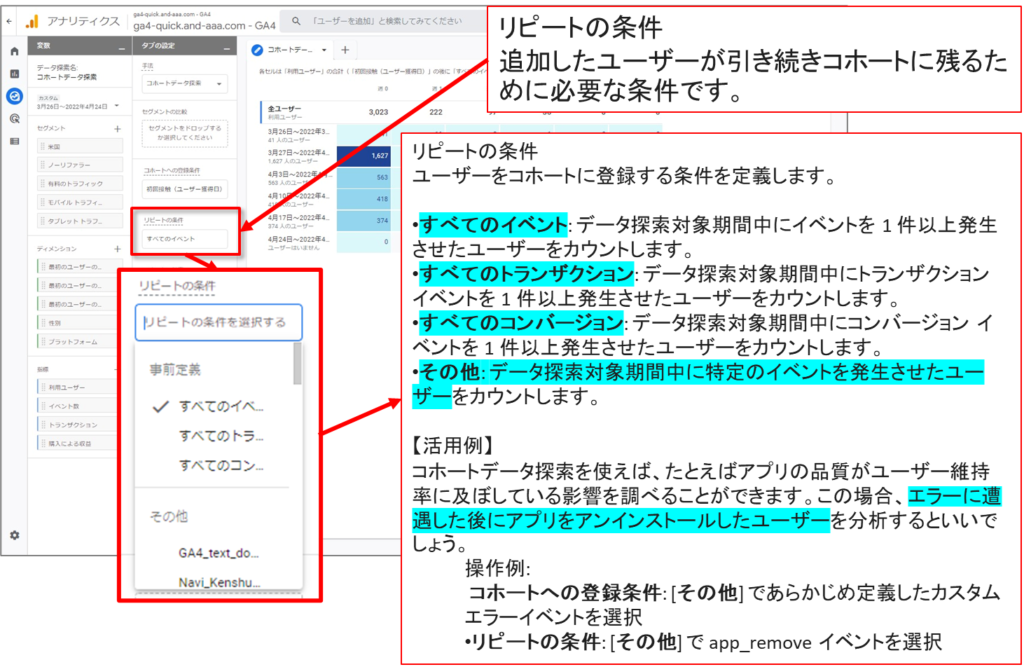
コホートデータ探索を設定する リピートの登録条件
コホートデータ探索の仕組み
コホートデータ探索では、まずはじめに、選択した登録条件とリピートの条件を満たすユーザーが抽出されます。コホートを作成する際は、ユーザーを獲得した日付、イベントの発生、トランザクションの発生、コンバージョンの発生を条件として使用できます。
コホートはユーザーのデバイスデータのみに基づいています。User-ID はコホートの決定では考慮されません。
コホートデータ探索では、各コホートを日、週、または月単位でグループ化します。データ表には、データ探索期間内の各コホートに属するユーザー数が表示されます。
データ表の各セルには、データ探索を開始した日以降にリピートの条件を満たしたユーザー数が示されます。たとえば粒度を日単位(「毎日」)に設定した場合、1 月 1 日のコホート(行)の [日 1] 列には、1 月 1 日に登録条件を満たし、かつ 1 月 2 日にリピートの条件を満たしたユーザー群が表示されます。
ユーザーは、登録条件を満たすすべてのコホートに割り当てられます。たとえば、登録条件にトランザクションを選択すると、データ探索期間に毎週トランザクションを完了したユーザーは、表の各行(コホート)に割り当てられます。
コホートデータ探索のUI
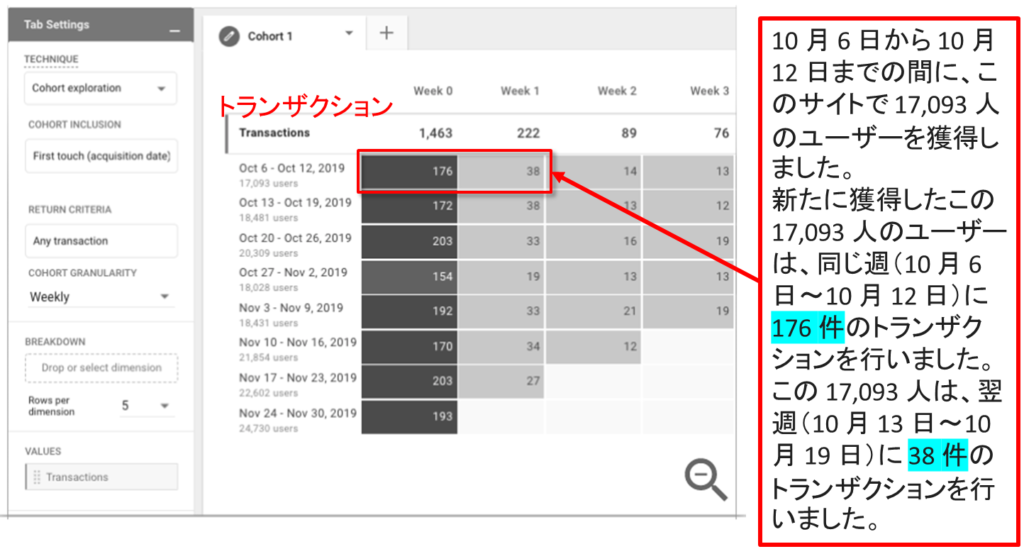
コホートデータ探索を理解する 例1
ホートデータ探索を理解する 例2
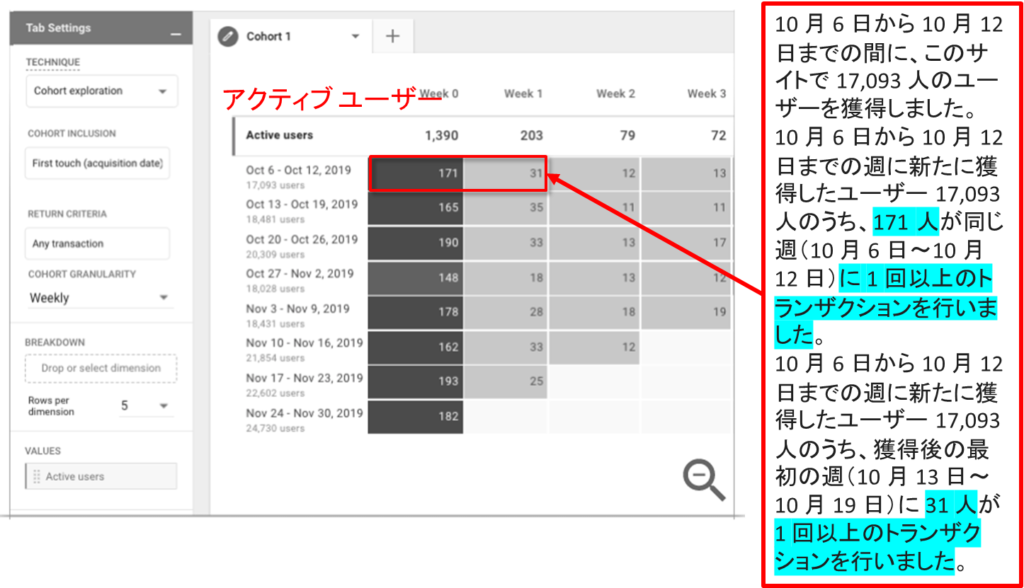
人数で見ているので、一つ上のデータよりも、数値が少なくなっています。
ホートデータ探索を理解する 例3
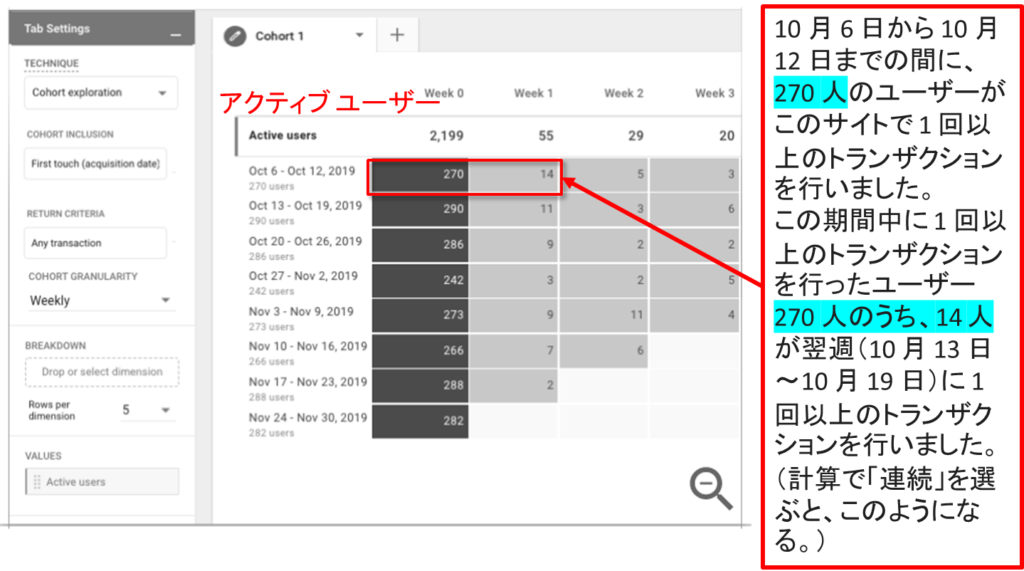
ホートデータ探索を理解する 例4
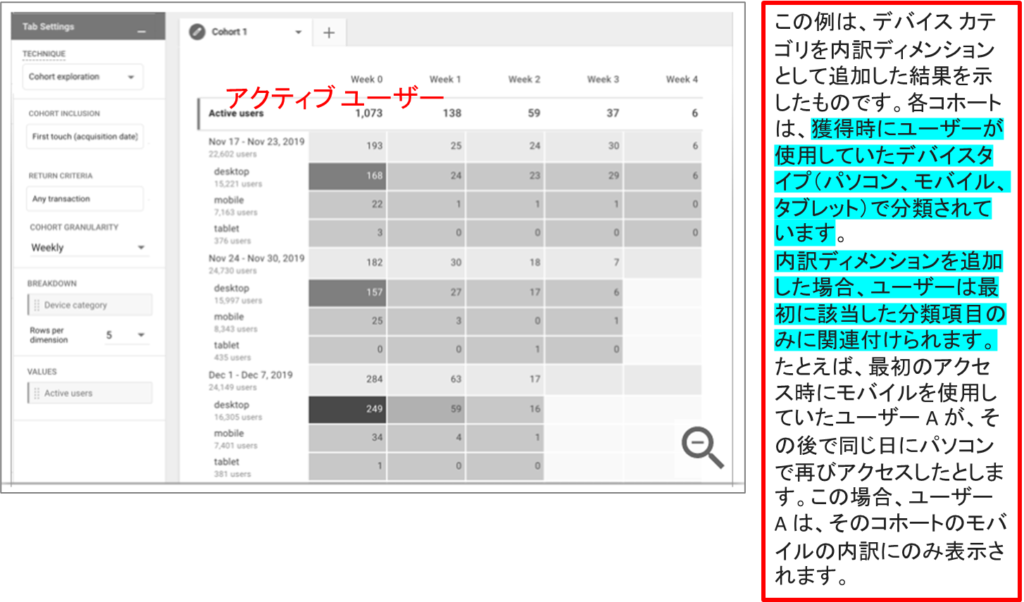
コホートデータ探索の制限事項
•コホートデータ探索で表示されるコホートは、最大 60 件までです。
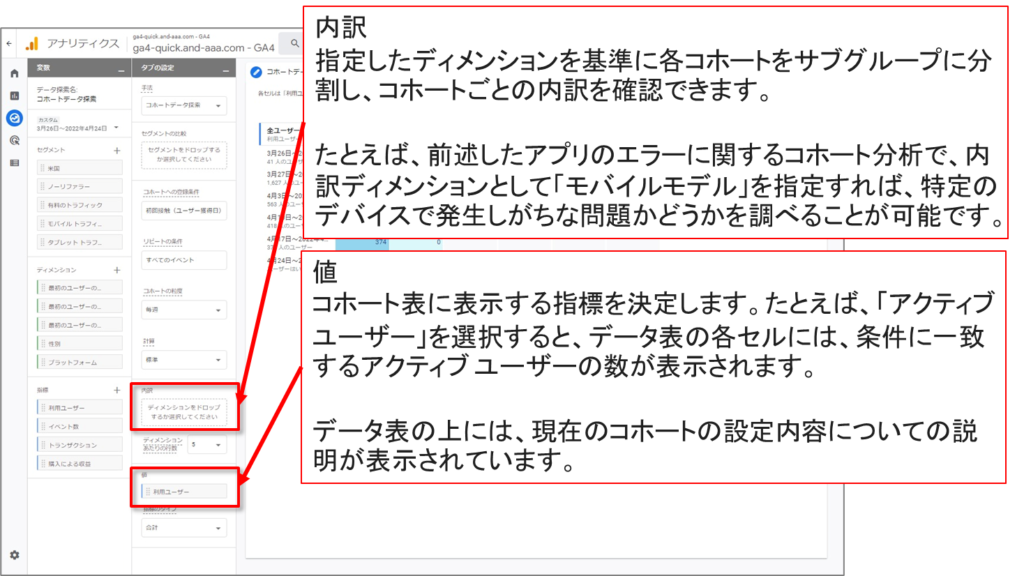
•内訳ディメンションを適用すると、そのディメンションの上位 15 個までの値が表示されます。
•ユーザー属性のディメンションには、しきい値が適用されます。コホートのユーザー数が少なすぎて匿名性を確保できない場合、それらのユーザーはデータ探索に含まれません。
ユーザーのライフタイム
ユーザー ライフタイム手法を使うと、サイトまたはアプリの顧客としてのライフタイムにおけるユーザー行動を理解できます。この手法では次のようなインサイトを得ることができます。
•選択した月のみの収益と比較して、最も高いライフタイム収益をもたらした参照元 / メディア / キャンペーン。
•価値が高いと期待されるユーザー(Google アナリティクスの予測モデルで、購入の可能性が高く、離脱の可能性が低いと予測されたユーザー)を獲得している有効なキャンペーン。
•ユニーク ユーザーの行動に関するインサイト(1 か月のアクティブ ユーザーがサイトで商品を最後に購入した日時や最後にアプリを利用した日時など)
公式ヘルプ:https://support.google.com/analytics/answer/9947257?hl=ja&ref_topic=9266525
「ユーザーのライフタイム」テンプレートを選択します。
ライフタイム データは、サイトやアプリで 2020 年 8 月 15 日以降アクティブだったユーザーにのみ使用できます。ユーザー ライフタイム手法で利用できるデータ範囲には、そうしたユーザーが初めてサイトかアプリを利用して以来のすべてのデータが含まれます。たとえば、2019 年 12 月に初めてサイトにアクセスしたものの、2020 年 8 月 14 日にアクティブでなくなったユーザーのデータは含まれませんが、そのユーザーが 2020 年 8 月 16 日にアクティブだった場合は、前の年(=2019年)にまで遡ってすべてのデータが含まれます。
ユーザー ライフタイム手法では、サイトまたはアプリのユーザーの集計データが表示されます。具体的には、ユーザーごとに次の情報を確認できます。
•最初の接点: プロパティでユーザーが初めて測定されたときに関連付けられたデータ(例: 初回訪問日や購入日、あるいはユーザーとして獲得されたキャンペーン)。
•最近の接点: プロパティでユーザーが最後に測定されたときに関連付けられたデータ(例: 最後にアクティビティや購入を行った日)。
•ライフタイムの接点: ユーザーのライフタイムにわたって集計されたデータ(例: ライフタイム全体の収益やエンゲージメント)。
•予測指標: ユーザーの行動を予測するために機械学習によって生成されるデータ。
例:
•購入の可能性
•アプリ内購入の可能性
•離脱の可能性
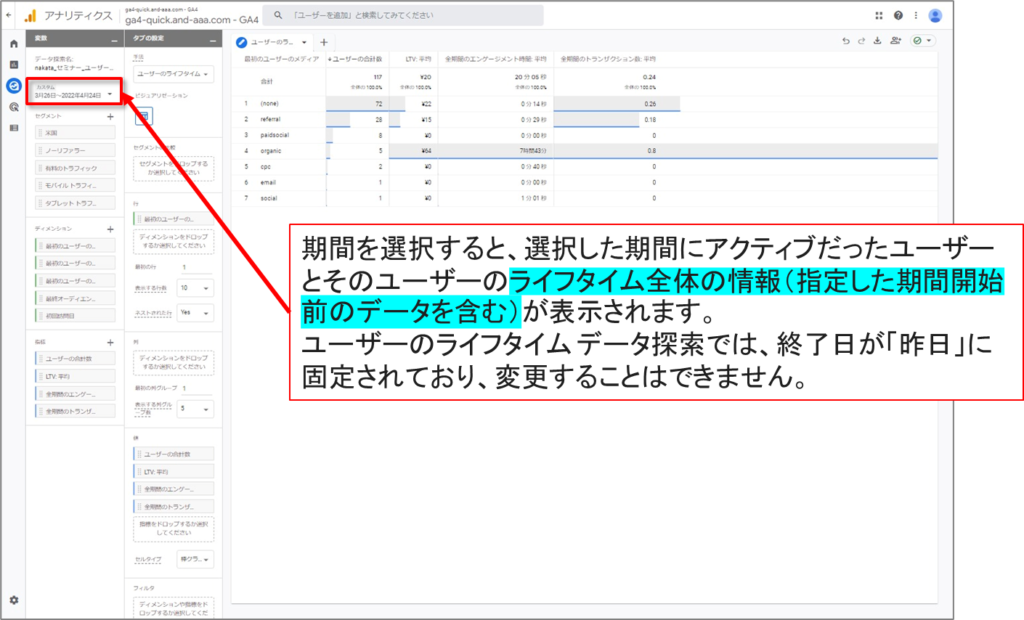
ユーザーのライフタイム データ探索の期間
ユーザーのライフタイム データ探索とレポートでのユーザー識別方法
GA4プロパティの User-ID 機能を使用すると、プラットフォームとデバイスをまたいだユーザーの識別とレポートの作成が 2 通りの方法で可能になります。レポートの際にプロパティで使用されるユーザーの識別方法には以下の 2 つがあります。これにより、ユーザーのライフタイム データにそれぞれ次のような影響があります。
まずは User-ID、次にデバイス ID
この方法では、ユーザーを判別し、レポートやデータ探索において関連イベントをまとめて扱うための識別情報として、より精度の高いユーザー ID をまず使用します(収集されている場合)。ユーザー ID が収集されていない場合は、デバイス ID(ウェブサイトの場合はクライアント ID、アプリの場合はアプリ インスタンス ID)を使ってユーザーを識別します。
選択した期間内に、あるユーザーに、ログインした状態とログアウトした状態の両方のアクティビティが発生した場合、データ探索にはユーザーのライフタイム データのログイン部分のみが使用されます。これにより、ユーザーデータがより正確になります。つまり、ユーザー数の重複はなく、平均ライフタイム バリュー(LTV)などの指標は User-ID に基づいてより正確に生成されます。ユーザーがログインしていないときに発生したアクティビティはデータ探索に含まれません。
デバイス ID のみ
デバイス ID(ウェブサイトの場合はアナリティクス Cookie、アプリの場合はアプリ インスタンス ID)でユーザーを識別し、ユーザー ID が収集されても無視します。この方法では、ユーザーのライフタイム データはデバイス単位で集計されます。
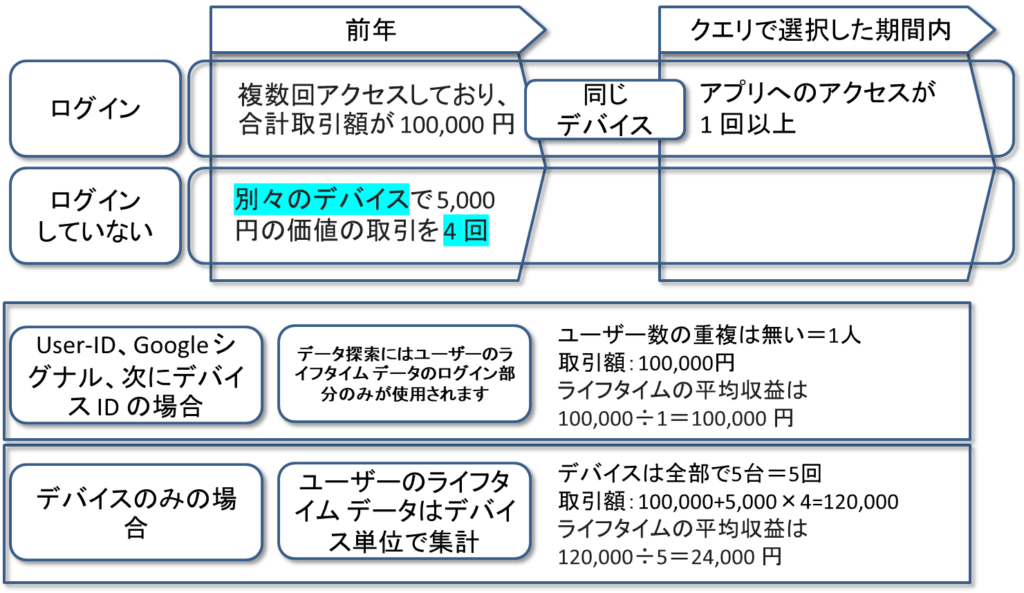
例(以下の文章を下記で図式化してあります。)
ログインしているユーザーが前年にアプリに複数回アクセスしており、合計取引額が 100,000 円だとします。同じユーザーが、ログインせずにゲストとして別々のデバイスで 5,000 円の価値の取引を 4 回行いました。それに加えて、クエリで選択した期間内に、ログインした状態でのアプリへのアクセスが 1 回以上あったとします。
ユーザーのライフタイム データ探索でこのユーザーのデータがどのように表示されるかは、使用するレポートでのユーザー識別方法によって異なります。
User-ID、Google シグナル、次にデバイス ID の場合: ログインデータのみがデータ探索の対象となるため、このユーザーは計 1 回カウントされ、100,000 円の収益があるとされます。ライフタイムの平均収益は 100,000 円になります。
デバイスのみの場合: このユーザーは 5 回カウントされます。そのうち 1 回は 100,000 円、4 回は 5,000 円の収益です。ライフタイムの平均収益は 24,000 円になります。
上記の図の「User-ID、Google シグナル、次にデバイス ID の場合 とは?」
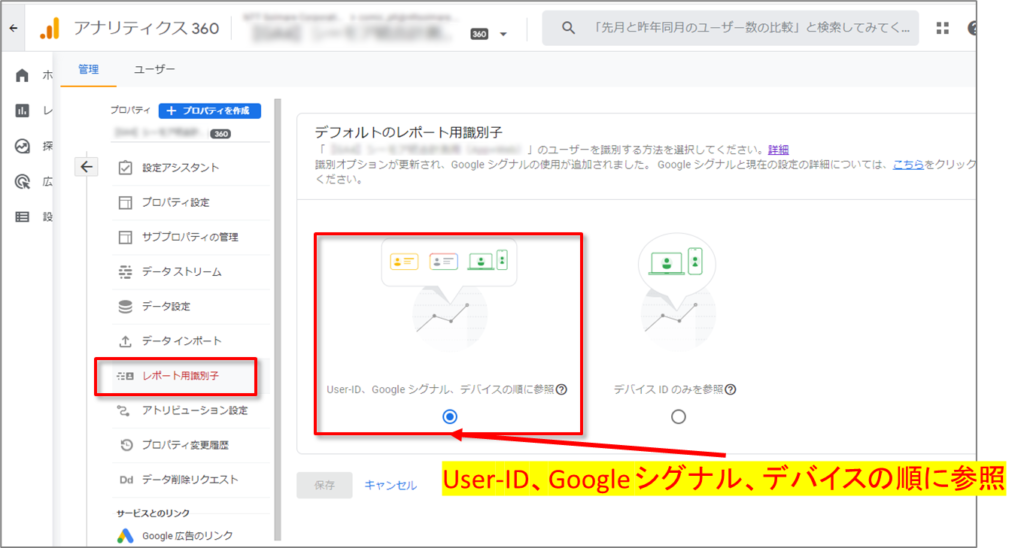
「管理 > レポート用識別子」 で設定する。収集用に送信する User ID、および同意済みユーザーを対象とする Google シグナルのデータに基づいて、複数のプラットフォーム間のユーザーのレポートを作成する場合は、このオプションを選択します。User ID が指定されていない場合、アナリティクスでは Google シグナルのデータが使用されます。このデータが利用できないときは、デバイス ID が使用されます。
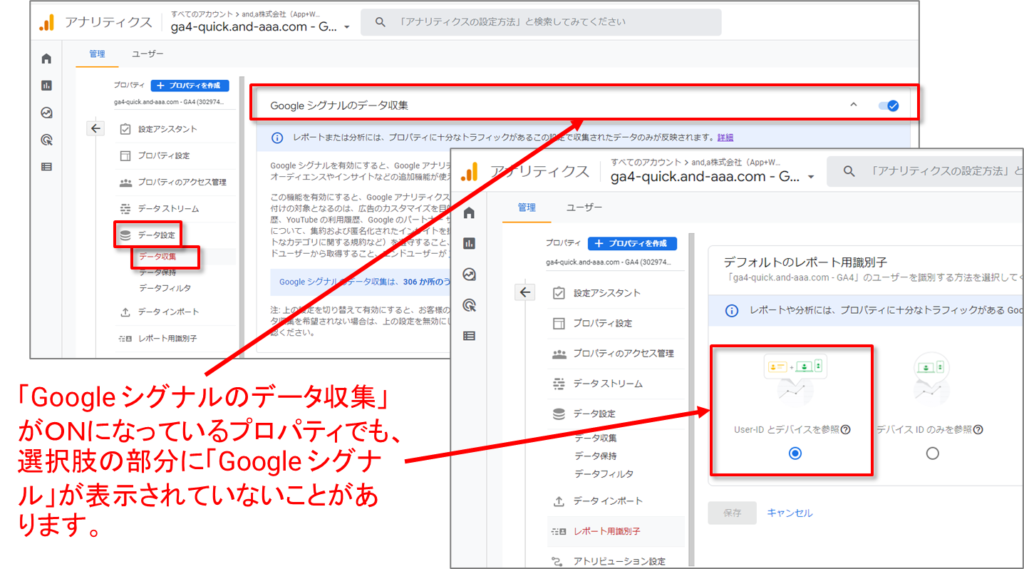
「Google シグナルのデータ収集」がON(管理 > データ設定 > データ収集)になっているプロパティでも、前ページで見た選択肢の部分に「Google シグナル」が表示されていないことがあります。
セグメントの重複
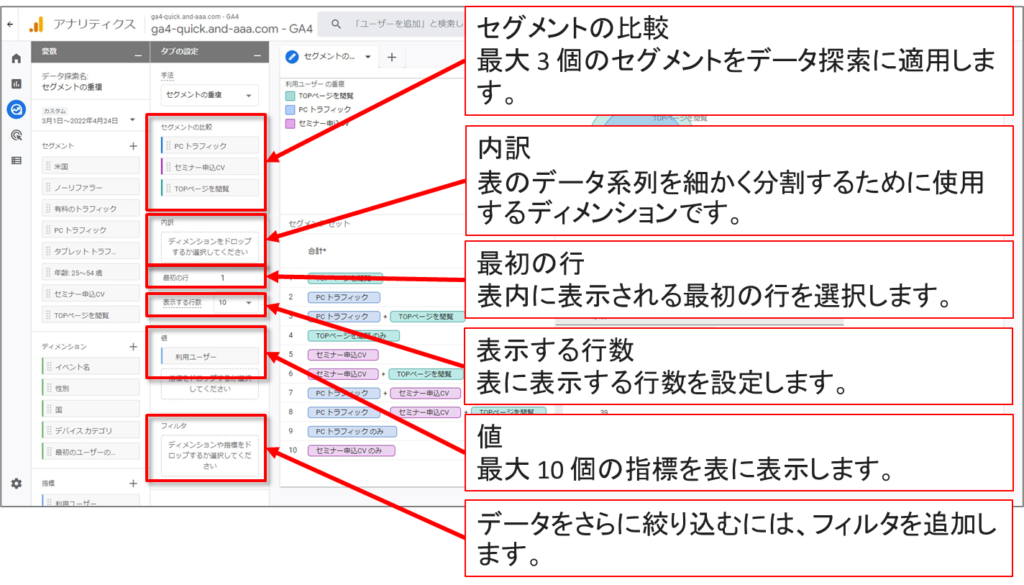
「セグメントの重複」手法を使用すると、最大 3 個のユーザー セグメントを比較して、それらの重複状況と相互関係をすばやく確認できます。この手法は、複雑な条件に基づいて特定のユーザーを見分ける際に役立ちます。見つかったユーザーから新しいセグメントを作成し、それを他のデータ探索の手法および Google アナリティクスのレポートに適用することもできます。
公式ヘルプ:https://support.google.com/analytics/answer/9328055?hl=ja&ref_topic=9266525
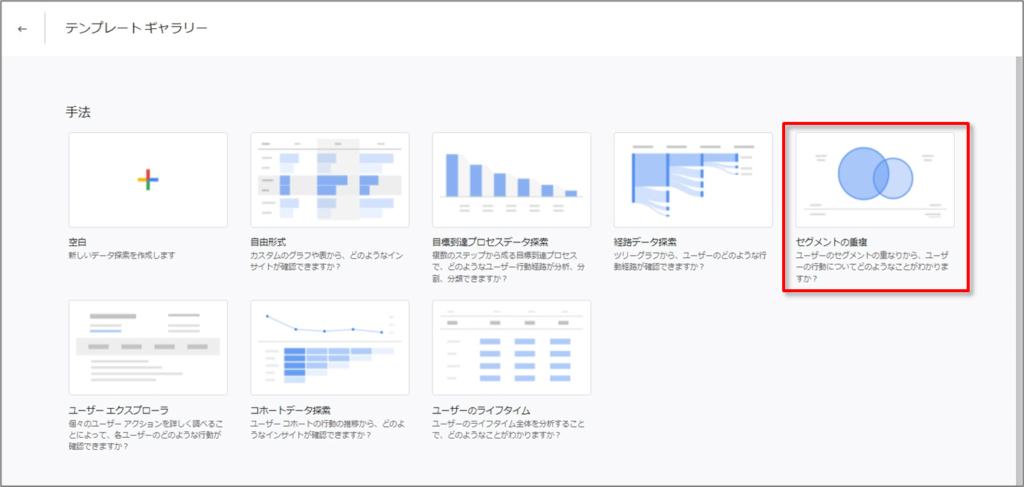
「セグメントの重複」テンプレートを選択します。
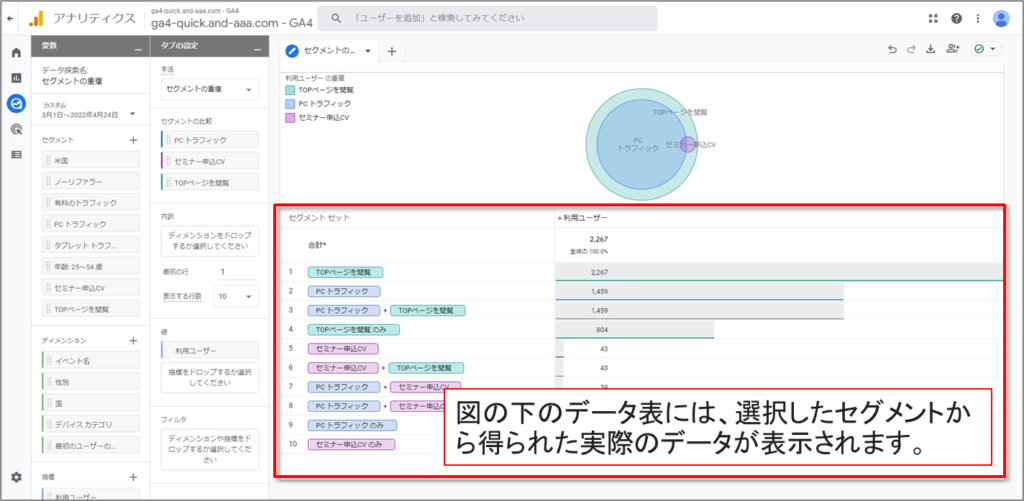
上記のデータ探索の例では、セグメントの重複を使用して、「TOPページを閲覧」、「PC トラフィック」、「セミナー申込CV」というセグメントが交わる部分を探っています。
セグメントの重複のUI
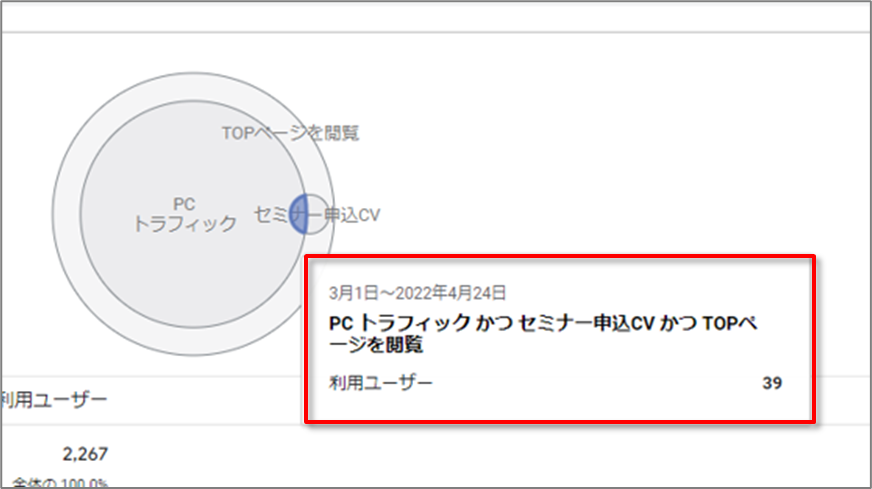
セグメントまたは共通部分(複数のセグメントが交わる部分)の内側にカーソルを合わせると、そのセグメントまたは共通部分について排他的な数値(他のセグメントと重なるすべての部分を除外した数値)が表示されます。

セグメントの枠線にカーソルを合わせると、そのセグメントについて両立的な数値(他のセグメントと重なるすべて部分を含めた数値)が表示されます。
セグメントの重複のデータから新しいセグメントを作成する
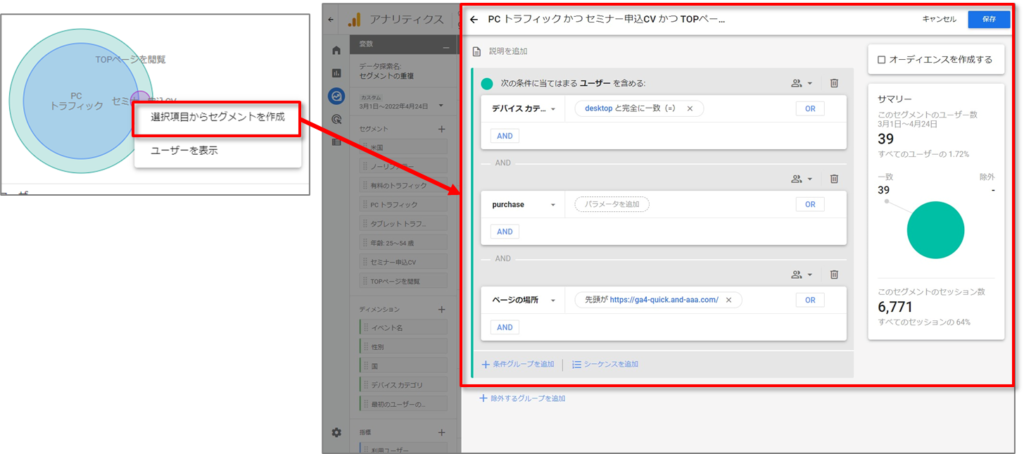
セグメントの重複のデータから新しいセグメントを作成するには、図内のセグメントか共通部分、またはデータ表のセルを右クリックします。たとえば、モバイル トラフィック、コンバージョンに至ったユーザー、新規ユーザーのすべての条件を満たす新しいセグメントを作成できます。
コメント